Internet et la vie privée
Sommaire
- 1 – Pourquoi protéger la vie privée
- 2 – Courrier électronique
- 3 – Le spam
- 4 – Trace sur Internet
- 5 – Les cookies: biscuits empoisonnées
- 6 – Les dangers du Web et des navigateurs
- 7 – Le commerce électronique
- 8 – Logiciel de blocage et technologie de censure
- 9 – P3P – Privacy Preferences Project
- 10 – Conclusion
- 11 – Les vidéos
- 11.1 - 3 Billion Yahoo Accounts Hacked
- 11.2 - Introduction to internet security
- 11.3 - Why is an IP address not an identity ?
- 11.4 - What is a browser cookie ?
- 11.5 - Sniffers les mots de passe
- 11.6 - Le chiffrement Symétrique
- 11.7 - Les clefs asymétriques
- 11.8 - Comprendre le Proxy et le Reverse Proxy en 5 minutes
- 11.9 - Why you shouldn't store passwords in your browser.
- 11.10 - Les clés symétriques et asymétriques
- 11.11 - La NSA piratent-ils nos données personnelles ?
- 11.12 - Smartphones et vie privée
- 11.13 - Le principe du chiffrement par clefs asymétriques
- 12 – Suivi du document
- 13 – Discussion autour de l’Internet et la vie privée
- Commentaire et discussion
- Laisser un commentaire
1 – Pourquoi protéger la vie privée
Internet a révolutionné la façon dont nous communiquons, en permettant un partage sans limites ni frontières de l’information. Cependant, avec l’appétit des nouvelles entreprises venues profiter de cette aubaine, il n’est pas surprenant de constater que la vie privée et la sécurité ont été les grands oubliés de cette révolution. La considérable augmentation des actes de violation de la vie privée et de la sécurité depuis la naissance d’Internet illustre parfaitement cette tendance alarmante.
A chaque fois que vous visitez un site Web sans être protégé, vous ne vous exposez pas seulement à un risque d’intrusion : vous fournissez quantité d’informations sur vous-même, qui peuvent inclure les pages que vous consultez habituellement, les mots-clés que vous recherchez, votre localisation géographique, votre adresse, votre numéro de téléphone, votre emploi, votre numéro de carte bancaire, etc. Beaucoup de ces sites compilent les informations, et conservent de véritables dossiers sur leurs visiteurs. Et même si, la plupart du temps, vous faites confiance à la personne qui est derrière le site que vous visitez, vos informations sont tout de même menacées en cas d’intrusion par des pirates.
Le droit à la vie privée ne se limite pas à la liberté de ne pas être dérangé et interrompu dans ses activités. Le pouvoir d’exercer un contrôle sur nos renseignements personnels est aussi un aspect essentiel de ce droit fondamental. À l’âge du numérique, où la collecte de données personnelles représente une valeur inestimable, la protection de la vie privée prend une importance de plus en plus grande.
Ce sont les quatre communs de la protection de la vie privée sur l’Internet:
- Anonymat: impossibilité (pour d’autres utilisateurs) déterminer le véritable nom de l’utilisateur associé à un sujet, une opération, un objet.
- Pseudonymité: idem, sauf que l’utilisateur peut être tenu responsable de ses actes.
- Non-chaînabilité: impossibilité (pour d’autres utilisateurs) d’établir un lien entre différentes opérations faites par un même utilisateur.
- Non-observabilité: impossibilité (pour d’autres utilisateurs) de déterminer si une opération est en cours.
Dans les parties suivantes, on va examiner les problèmes qui gênent les internautes, ou de plus, suscitent des problèmes sérieux pour eux.
2 – Courrier électronique
2.1 – Messagerie anonyme
2.1.1 – Messagerie anonyme, pour quoi faire ?
Imaginez que vous êtes l’administrateur d’un système sensible dans une grande entreprise. Cependant, vous êtes confronté à un problème technique que même votre fournisseur n’est pas en mesure de résoudre. Vous voudriez bien poser la question dans les news, mais vous n’avez pas envie que tout le monde prenne connaissance de la configuration de votre système, pour d’évidentes raisons de sécurité. De plus, vous tenez à votre réputation et ne souhaitez pas que tous vos collègues sachent que vous séchez lamentablement sur une difficulté, vous qui avez la réputation d’être un grand spécialiste.
Cet exemple conduit à la question: comment envoyer un message anonymement sur l’Internet. La méthode ici est simple; si vous ne voulez pas communiquer votre identité, et de saisir une adresse fictive dans votre logiciel de messagerie. Vous pensez ainsi être protégé. En réalité; il n’en est rien. Comme nous allons le voir plus loin, les entêtes de messagerie comportent nombre d’informations permettant non seulement de vous identifier mais également d’obtenir des renseignements sur votre ordinateur, votre logiciel de messagerie, etc.
Heureusement il existe des services sur l’Internet qui permettent d’envoyer des messages sans divulguer votre véritable adresse d’email. On trouve ici deux solution: les Webmails qui fournissent des services de messagerie qu’on peut accéder par le Web, et les relais anonymes.
Avant d’aborder ces deux services, on examine les entêtes de messagerie.
2.1.2 – Des entêtes qui parlent
Premièrement on voit un exemple d’une message avec le nom et l’adresse de l’expéditeur est anonyme (J’ai envoyé ce message en utilisant Microsoft Outlook, utilise le serveur mail de l’IFI). Ici, le nom est hello, et l’adresse email est hello@test.com, il peut-être n’existe pas.
Return-Path: <hello@test.com> Received: from Madagascar (madagascar.tpI.ifi [192.168.102.116]) by saturne.dorsale.ifi.edu.vn (8.11.0/8.11.0) with SMTP id h5EIs7A24919 for <pnlong@ifi.edu.vn>; Sat, 14 Jun 2003 11:54:07 -0700 Message-ID: <000a01c331ca$3c0dd480$7466a8c0@tpI.ifi.edu.vn> From: "hello" <hello@test.com> To: <pnlong@ifi.edu.vn> Subject: hello Date: Fri, 13 Jun 2003 23:38:35 +0700 MIME-Version: 1.0 Content-Type: multipart/alternative; boundary="----=_NextPart_000_0007_01C33204.E84CA160" X-Priority: 3 X-MSMail-Priority: Normal X-Mailer: Microsoft Outlook Express 5.50.4133.2400 X-MimeOLE: Produced By Microsoft MimeOLE V5.50.4133.2400 This is a multi-part message in MIME format. ------=_NextPart_000_0007_01C33204.E84CA160 Content-Type: text/plain; charset="iso-8859-1" Content-Transfer-Encoding: quoted-printable Hello hello
Malheureusement, la personne qui m’a envoyé ce message n’est pas experte en informatique. Dans le champ de type received au début, on peut voir l’expéditeur a utilisé la machine avec l’IP 192.168.102.116. La suite de l’entête nous donne davantage de renseignements, en particulier les lignes précédées de la lettre X. Ces champs n’étant pas standardisés, ils peuvent contenir n’importe quel type d’information.
X-Mailer: Microsoft Outlook Express 5.50.4133.2400
L’expéditeur a utilisé le logiciel de messagerie Microsoft Outlook version 5.5 pour rédiger le message. Ce renseignement pourrait nous servir si nous avions l’intention de lancer une attaque contre l’entreprise. En effet, la connaissance des logiciels employés nous permettrait de mettre en oeuvre des actions spécifiques à ceux-ci.
L’exemple ci-dessus prouve qu’un simple message peut contenir nombre d’informations sur l’expéditeur, con entreprise, son logiciel de messagerie ou encore son type d’ordinateur. Ici, c’est Windows 9x ou NT/2000. Heureusement, les services de messagerie accessibles via le Web peuvent constituer une solution aux problèmes soulevés ici, comme nous allons le voir maintenant.
2.1.3 – Webmail
L’expéditeur décide de créer un compte chez Hotmail. Et par exemple il ne donne pas ses vrais nom et prénom. Et l’expéditeur pense que: « de toute façon, ils ne pourront pas me trouver ». Et il m’envoie un message « anonyme ».
Return-Path: <cuong_h_to@hotmail.com> Received: from fw.ifi.edu.vn (mail.ifi.edu.vn [203.162.5.195] (may be forged)) by saturne.dorsale.ifi.edu.vn (8.11.0/8.11.0) with ESMTP id h5GHNT926335 for <pnlong@ifi.edu.vn>; Mon, 16 Jun 2003 10:23:29 -0700 Received: from hotmail.com (bay7-f109.bay7.hotmail.com [64.4.11.109]) by fw.ifi.edu.vn (8.11.6/8.11.0) with ESMTP id h5GA0Vs22135 for <pnlong@ifi.edu.vn>; Mon, 16 Jun 2003 03:00:32 -0700 Received: from mail pickup service by hotmail.com with Microsoft SMTPSVC; Sun, 15 Jun 2003 20:06:37 -0700 Received: from 203.162.5.197 by by7fd.bay7.hotmail.msn.com with HTTP; Mon, 16 Jun 2003 03:06:37 GMT X-Originating-IP: [203.162.5.197] X-Originating-Email: [cuong_h_to@hotmail.com] Fr-om: "Cuong Huy To" <cuong_h_to@hotmail.com> To: pnlong@ifi.edu.vn Subject: Day la thu hack day Date: Mon, 16 Jun 2003 10:06:37 +0700 Mime-Version: 1.0 Content-Type: text/plain; format=flowed Message-ID: <BAY7-F109tQvAauNjVu00004368@hotmail.com> X-OriginalArrivalTime: 16 Jun 2003 03:06:37.0980 (UTC) FILETIME=[4D41E5C0:01C333B4] Ha ha
On trouve ici un entête similaire à celui étudié plus haut. Le champs Received fournie aucune information sur l’origine du message puisqu’il ne transite que du site Web de Hotmail vers le serveur SMTP. De plus, nous ne savons pas quel navigateur a été employé. Mais il y a une ligne assez curieuse:
X-Originating-IP: [203.162.5.197]
Une adresse IP a en effet ajoutée à l’entête du message. Cette adresse est tout simplement celle de la machine de l’expéditeur. Ce champs soulève le problème: il est difficile à parler d’anonymat. Mais il y a des autres services de messagerie qui ne fait pas apparaître l’adresse IP de l’expéditeur comme Caramail. Mais ce n’est pas sur par ce que les services peuvent changer ses comportements demain.
2.1.4 – Les relais anonymes
Les remailers anonymes fonctionnent tous selon le même principe: il s’agit de faire transiter un message entre plusieurs serveurs SMTP relais, lesquels ont la capacité de supprimer non seulement les champs Received ajoutés par les serveurs précédents, mais également toutes les informations permettant d’identifier l’expéditeur telles celles que nous avons vues jusqu’ici. Ainsi, seule le nom du dernier serveur apparaît dans l’entête. Il est impossible à un internaute moyen de remonter à l’expéditeur.
Par exemple, J’utilise le service à http://anony.co.uk/ pour envoyer un message à pnlong@ifi.edu.vn. La source de message est présentée ci-dessous :
Return-Path: <nobody@host.union-server.com> Received: from fw.ifi.edu.vn (mail.ifi.edu.vn [203.162.5.195] (may be forged)) by saturne.dorsale.ifi.edu.vn (8.11.0/8.11.0) with ESMTP id h5GIK2927313 for <pnlong@ifi.edu.vn>; Mon, 16 Jun 2003 11:20:02 -0700 Received: from host.union-server.com ([64.191.60.135]) by fw.ifi.edu.vn (8.11.6/8.11.0) with ESMTP id h5GAv2s22330 for <pnlong@ifi.edu.vn>; Mon, 16 Jun 2003 03:57:04 -0700 Received: from nobody by host.union-server.com with local (Exim 3.36 #1) id 19RlCr-0005a7-00 for pnlong@ifi.edu.vn; Mon, 16 Jun 2003 05:02:57 +0100 To: pnlong@ifi.edu.vn Subject: Hello Content-Type: text/html; charset=windows-1254 From: "Ten Ten " <hehe@linhtinh.com> X-Mailer: * Message-Id: <E19RlCr-0005a7-00@host.union-server.com> Date: Mon, 16 Jun 2003 05:02:57 +0100 X-AntiAbuse: Sender Address Domain - host.union-server.com Hello Hello hack <br>-----<br> <font size=1>*
Vous pouvez constater que les champs qui nous permettent de trouver l’expéditeur ont été supprimé. Par ailleurs qu’il est vraiment indiqué que le message est anonyme.
2.2 – Messagerie sécurisée
2.2.1 – Généralité
Dans quelque condition, comment on peut avoir la certitude qu’un message comportant gates@microsoft.com comme adresse d’expéditeur a été émis par le fondateur de Microsoft. De plus, il est important de noter que tout message transmis sur le réseau est en clair. Cela signifie que n’import qui peut l’intercepter et en prendre connaissance. Une personne peut modifier un message qui vous est destiné, sans la possibilité de vous en rendre compte.
En utilisant des algorithmes ou protocole cryptographiques, on peut assurer à tout message les propriétés suivantes :
- Confidentialité: seul le destinataire d’un message peut en prendre connaissance
- Intégrité: un message ne peut être modifié à l’insu du destinataire
- Authentification: l’identité de l’expéditeur peut être vérifié
- Non répudiation: l’expéditeur ne peut nier avoir émis un message un fois le message reçu par son destinataire.
Plus précisément, on utilise le chiffrement pour assurer la confidentialité d’un message et à des mécanismes de signature pour l’intégrité, l’authentification et la non répudiation.
2.2.2 – Certificat
Le certificat numérique permet les gens, les organisations, les entreprises sur l’Internet à vérifier les uns et les autres.
Qu’est ce que c’est un Certificat :
Il y a plusieurs types ou classes de certificat (chaque classe correspond un certain niveau de confiance que l’on peut accorder à un certificat. Plus précisément, un certificat de classe 1 sera moins sûr qu’un certificat de classe 2), mais au niveau le plus élémentaire, un certificat est un identifié combiné avec une clé publique, et signé par une Autorité de Certification (AC, CA en anglais). Lorsqu’on a un certificat, on peut l’utiliser de plusieurs façons dont les deux opérations principales sont l’authentification et le cryptage. Ces deux opérations dépendent de la concept du chiffrement avec la clé publique.
En réalité, il y a quatre types de certificat utilisés sur l’Internet actuellement :
- Certificat du AC: contient la clé publique d’un AC, et le nom du AC ou le nom du service particulière. Ce type de certificat est utilisé pour certifier les autres types de certificat.
- Certificat de serveur: contient la clé publique d’un serveur de SSL, le nom de l’organisation qui est le propriétaire du serveur, son nom d’hôte d’Internet, et la clé publique du serveur.
- Certificat personnel: (ou certificat de client) Ces certificats contiennent un nom d’un individu et sa clé publique. Ils peuvent avoir l’autre information aussi, tel que l’adresse d’e-mail de l’individu, l’adresse postale, ou n’importe quoi autrement.
- Certificat de publication de logiciel: utilisé pour signer les logiciels distribués.
On va expliquer ici le certificat de client.
L’identité ID dans un certificat (on l’appelle souvent le « sujet » du certificat) identifie qui est le propriétaire du certificat. Il peut avoir des syntaxes variées, mais il contient un nom distingué avec des attributs comme le « nom commun » (CN), l’organisation (O), l’unité de l’organisation (OU). Le sujet du certificat a des entrées supplémentaires comme l’adresse email ou le nom de la domaine. (ex: www.ifi.edu.vn)
La clé publique est une partie du pair clé publique/privée. La clé privée n’est pas une partie du certificat et elle n’est jamais transférée sur la ligne de communication. Une personne qui veut contacter le sujet du certificat peut utiliser la clé publique comme une partie de l’algorithme de cryptage.
En réalité, la signature du AC garantie l’identité réelle du sujet du certificat. Par exemple, un AC peut exiger le sujet (le propriétaire du certificat) de présenter quelques images d’indentification avant de signer le certificat.
Voila un exemple de certificat. Dans le certificat, on peut voir le champ « Issuer » (le AC qui a distribué le certificat), le champ « Subjects » (l’identité du propriétaire du certificat), le champ « Publique Key » (la clé publique du sujet), et le champ « Signature » (le signature du AC qui a garantie le sujet).
Certificate: Data: Version: v3 Serial Number: 0x7 Signature Algorithm: MD5withRSA - 1.2.840.113549.1.1.4 Issuer: CN=Certificate Manager,OU=iPlanet,O=pki.ilabs.interop.net Validity: Not Before: Saturday, April 14, 2001 6:47:23 PM PST Not After: Sunday, April 14, 2002 6:47:23 PM PM PST Subject: CN=Joel Snyder,OU=users,O=pki.ilabs.interop.net Subject Public Key Info: Algorithm: RSA - 1.2.840.113549.1.1.1 Public Key: Exponent: 65537 Public Key Modulus: (1024 bits) : <ici est une chaîne de caractère longue qui se présente la clé publique> Extensions: Identifier: Key Usage: - 2.5.29.15 Critical: yes Key Usage: Digital Signature Non Repudiation Key Encipherment Identifier: Subject Alternative Name - 2.5.29.17 Critical: no Value: [RFC822Name: jms@opus1.com] Signature: Algorithm: MD5withRSA - 1.2.840.113549.1.1.4 Signature: <ici est une chaîne de caractère longue qui se présente la signature du AC>
2.2.3 – Utiliser les gérer des certificats
Signer un message
D’une façon générale, dès que l’on dispose un certificat, il est nécessaire de le diffuser à tous nos correspondants de façon qu’ils puissent vérifier l’authenticité et l’intégrité des messages. La méthode la plus simple pour transmettre un certificat consiste à signer un message et à l’envoyer à qu’un.
Authentification et le cryptage
Les certificats peuvent être utilisés pour authentifier le propriétaire du certificat (par exemple dans la négociation avec le protocole SSL). En utilisant le chiffrement asymétrique et un des nombres d’algorithme, il est possible de prouver l’identité. Le certificat peut être utilisé pour le cryptage. Mais à cause de la lenteur de calcul il est seulement utilisé pour crypter quelques octets de donnée.
Récupérer le certificat d’un correspondant
Supposons que Bob veut envoyer un message très important à Alice, mais qu’il ne dispose pas de son certificat et que celle-ci ne soit pas en mesure de le lui envoyer. Comment Bob peut-il procéder? Il existe en réalité plusieurs solutions. Les AC ne se contentent pas en effet de délivrer des certificat, elles gèrent aussi des annuaires contenant les certificats de leurs clients, d’où la possibilité de récupérer un certificat sans l’intervention de son titulaire. Toutes les AC proposent ce type de service par l’intermédiaire d’un moteur de recherche accessible à l’aide d’un navigateur Web (ex:http://www.belsign.be/fr/services/find/index.html). Cependant, les annuaires des plus connus peuvent être consultés directement par l’intermédiaire d’une commande spécifique à un logiciels tel que Outlook Express ou Messenger, via le protocole LDAP. LDAP – Lightweight Directory Access Protocol, est un protocole d’Internet que les programmes de messagerie peuvent utiliser pour obtenir les informations de contact d’un serveur.
Révoquer un certificat
Une clé privée est une information sensible qu’il faut impérativement protéger contre la divulgation ou la perte. Lorsqu’une clé ne peut plus être employé, il est fondamental de prévenir tous ceux qui possèdent le certificat qui lui est associé afin qu’ils ne l’utilisent plus dans le but de chiffrer des données ou vérifier des signatures. Il ne serait cependant pas envisageable pour une AC de contacter une à une chacune des personnes possédant un certificat compromis, d’autant plus qu’elle ne dispose pas de la liste de ces personnes. C’est pourquoi il existe des listes de certificats révoqués contenant les identifiants des certificats qui ne doivent plus être considérés comme valides, même si leur date d’expiration n’a pas été atteindre. L’opération qui consiste à signifier à une AC qu’un certificat délivré par elle doit être invalidé s’appelle la révocation.
2.2.4 – Quelques mots sur PGP
PGP (Pretty Good Privacy) est un logiciel développé au début des années 1990s par Phil Zimmermann. Sa diffusion a été particulièrement remarquée pour des raisons juridiques mais également parce qu’il s’agissait du premier logiciel mettant en oeuvre de la cryptographie forte, gratuit. PGP repose sur un système volontairement décentralisé où aucune autorité n’est employée afin de certifier les clés publiques des différents utilisateurs. En fait, PGP utilise des chaînes de confiance permettant d’authentifier un certificat: si Bob reconnaît la signature d’Alice, il pourra reconnaître du même coup toutes les clés publiques que Alice signera et auxquelles elles aura explicitement accordé sa confiance.
En pratique, on intègre PGP, un programme totalement autonome, à un logiciel de messagerie à l’aide de modules supplémentaires appelés plugin. Il existe de tels modules pour Outlook …. Une fois installés, ces plugins ajoutent des menus ainsi que des icônes qui permettent d’accéder aux fonctionnalité de PGP, à savoir le chiffrement et la signature de messages.
3 – Le spam
3.1 – Généralité
Le spam est à la messagerie électronique ce que sont les prospectus publicitaires aux boîtes aux lettre: des messages diffusés indifféremment à des milliers de personnes. Les spams sont véhiculés à travers deux médiums principaux: l’email et les conférences (newsgroups).
3.1.1 – Type de spam
Les spams sont fréquemment classés en plusieurs catégories, qu’ils soient diffusés par courrier électronique ou dans les conférences.
Les spams dans le courrier électronique :
- UBE (Unsolicited Buld Email), ou mailing non sollicité, désigne généralement le spam dans son ensemble: un même message envoyé à des dizaines de milliers de personnes dans qu’elles l’aient explicitement demandé.
- UCE: (Unsolicited Commercial Email) et un cas particulier de l’UBE limité aux spams à caractère commercial, c’est à dire qui proposent un produit ou un service contre une certaine somme d’argent.
- Les messages MLM (Make Money Fast) garantissent d’importants gains en des temps records à condition que chaque destinataire envoie une somme modique (un dollar par exemple) à chacune des personnes inscrites sur une liste incluse dans le message, ajoute ses coordonnées en tête de celle-ci. Puis transmettre le message ainsi modifié à un maximum d’internautes.
- Les messages MLM (Multi Level Marketing) invitent leurs destinataires à intégrer des systèmes de vente pyramidale dans l’espoir de faire fortune contre un investissement initial relativement faible.
Le spam dans les conférences
- EMP: est une pratique qui consiste à envoyer de nombreux articles identiques dans des dizaines de conférences, sans tenir compte du thème et la charte celle-ci. Ils les polluent tout en encombrant les serveurs NNTP qui les reçoivent.
- ECP: (Excessive Cross Posting) consiste à envoyer en une seule fois un même article dans des dizaines de conférences. La différence entre EMP et ECP est que dans le second cas, l’article est stocké dans un seul exemplaire sur chaque serveur et, généralement, il n’est présenté qu’une seule fois aux personnes qui consulteraient plusieurs des conférences visées.
Un caractéristique classique d’un message commercial non sollicité est que les adresses source et de destination sont manifestement fictives, l’émetteur ne veut pas recevoir des milliers de message de protestation. Les produits proposé dans les messages ne sont à l’évidence pas très officiels.
3.2 – Les techniques de spammeur
La meilleure façon de lutter contre un agresseur est de connaître les technique qu’il emploie. Dans le cas du spam, nous nous proposons de voir comment les spammeurs procèdent pour constituer leurs listes d’adresse email, puis envoyer des milliers de messages identiques à partir de ces listes.
3.2.1 – Obtention d’adresses email
L’objectif étant de toucher un maximum de personne, ces listes doivent comporter un nombre important d’adresse valide. Le spammeur peut constituer lui-même ses propre listes, ou il achète une ou plusieurs listes à une société de commercialisation directe spécialisée dans le spam. Dans les deux cas, ces listes sont constituées à partir de plusieurs sources, dont voici les principales :
- Les conférences: avec les outils spéciaux, on peut extraire les adresses contenues dans les articles stockés sur un serveur NNTP.
- Les pages Web: les pages Web peuvent contenir plusieurs adresses email aussi.
- Les listes de diffusion: les spammeurs peuvent parfois obtenir la liste des personnes abonnées à une certaine liste, permettant ainsi de constituer quasi instantanément une liste importante d’adresse valide.
- Les annuaires d’utilisateur: On rencontre sur l’Internet de nombreuses bases de données contenant parfois des centaines de milliers, voire des millions d’adresses. Il peut tout simplement s’agir d’annuaires de messagerie, où chaque internaute est invité à s’inscrire librement de façon que ses amis puissent retrouver son adresse email.
- Les utilisateurs enregistrés de certains services ou logiciels: nombre de sociétés demandent eux internaute souhaitant tester un produit ou accéder à un service de remplir un formulaire contenant, entre autres, leur adresse email. Les listes peuvent être vendues.
3.3 – Lutter contre le spam
3.3.1 – Mesures préventives
On commence par des solutions particulièrement simples et faciles mises en oeuvre pour éviter de recevoir du spam. Utiliser deux adresses La solution idéale pour s’affranchir du spam est de définir deux adresses : l’une privée, et l’autre publique. L’adresse privée sera l’adresse principale, qu’on ne communiquera qu’à des collègues et amis. Quand à l’adresse publique, elle sera utilisée pour poster des articles dans les conférences, s’inscrire à des listes de diffusion …
Dans les conférences
Une des techniques contre le spam les plus utilisées dans les conférences est le camouflage d’adresse, lequel consiste de modifier cette dernière de telle façon que seul l’humain soit capable de reconstituer l’adresse originale. Les outils utilisés par des spammeurs sont alors incapables (ou avoir de difficulté) de l’obtenir. Ex : une adresse pnlong@ifi.edu.vn peut changer en pnlongàifiPOINTeduPOINTvn.
Pourtant, le camouflage d’adresse doit respecter un certain nombre de règles. En particulier, il faut s’assumer de ne pas indiquer une adresse qui pourrait malgré tout exister. On ne doit pas non plus ajouter une quelconque chaîne de caractères avant le nom de domaine réel ou à gauche du signe @, car dans les deux cas, un éventuel message envoyé à une telle adresse sera automatiquement dirigé vers le serveur de messagerie. Ex: si je modifie mon adresse de pnlong@ifi.edu.vn à etudiantpnlong@ifi.edu.vn ou à pnlongetudiant@ifi.edu.vn ou pnlong@haha.ifi.edu.vn. Un message envoyé à des adresses listés ici est dirigé vers le serveur d’email (ifi.edu.vn).
Sur le Web
Sur le Web, la technique de camouflage est tout d’abord possible employée. Une autre solution classique est d’indiquer l’adresse de messagerie dans une image non cliquable.
Les opt-in et opt-out
Quand on s’inscrit à un service, ou télécharge un logiciel gratuit par exemple, les sites Web peuvent demander l’adresse d’email et, de plus, peuvent proposer des listes de diffusion des informations, telle que les informations sur des produits d’une entreprise quelconque. On trouve ici les stratégies de commercialisation: l’opt-in et l’opt-out. L’opt-in et l’opt-out, c’est la manière dont sont collectées les données personnelles (en particulier des adresses électroniques) des internautes. On distingue quatre possibilités d’inscription d’un internaute à une liste de diffusion. Dans la liste qui suit, la liberté de choix de l’internaute est de plus en plus réduite.
- L’opt-in actif : l’internaute doit volontairement cocher une case ou faire défiler un menu déroulant pour que son adresse (ou d’autres données) soient utilisées ultérieurement à des buts commerciales.
- L’opt-in passif : une case est déjà précochée ou un menu déroulant déjà positionné sur oui (à la question voulez-vous recevoir des sollicitations ultérieures ?). Avec l’opt-in, l’accord de l’internaute est explicite.
- L’opt-out actif : Il faut cocher une case ou sélectionner un menu déroulant pour ne pas recevoir de message ultérieurement. On considère l’accord de l’internaute comme acquis par défaut, comme implicite.
- L’opt-out passif : en s’inscrivant à un service, l’internaute est automatiquement inscrit à une liste de diffusion sans qu’il ait la possibilité de changer cela au moment de l’inscription. La désinscription ne peut se faire qu’après l’inscription. L’accord de l’internaute est demandé à posteriori.
Pour l’opt-out passif, l’internaute ne peut pas éviter les messages envoyés par des entreprises de commercialisation. Pour les trois premiers cas, les messages vont être envoyés l’internaute a accepté la publicité proposée par le site Web.
Aujourd’hui La légitimité des opt-in et opt-out est encore disputée: en Europe, aux Etats Unis, et en France.
3.3.2 – Filtrage à l’arrivée
Il va donc d’un filtrage effectué via un logiciel de messagerie à partir des messages reçus dans la boîte aux lettres. On ne traiterons ici que le cas des utilisateurs qui se connectent à un serveur POP3 afin de récupérer leur courrier électronique stocké sur une machine distante.
Les logiciels de messagerie comme Mozilla ou MS Outlook intègrent des filtres qui permettent de déplacer un message vers un dossier particulier en fonction d’un certain nombre de critères définissables par l’utilisateur, liés aux différents champs constituant l’entête d’un message, voire même à son contenu.
Pour pouvoir filtrer les spams, il va falloir trouver un ou plusieurs critères permettant de les identifier dans la plupart des cas. La solution la plus simple consiste à utiliser une liste d’adresse employées par des spammeurs. Chaque fois qu’on détecte un message comportant une adresse appartenant à cette liste. On sait que c’est un spam. Malheureusement, cette technique n’est jamais efficace à 100%.
Il existe une solution plus simple particulièrement efficace. Il faut savoir que la plupart des message de spam ne contiennent pas l’adresse email de la personne qui les reçoit. Ceci est du au fait que les spammeurs utilisent le champ Bcc: leur permettant d’envoyer en une fois un même message sans que la liste des destinataires ne vienne encombrer son contenu.
Le stratégie ici va donc déplacer vers un répertoire spécifique, voir effacer, tout message ne vous étant pas directement adressé. C’est à dire dans l’entête duquel votre adresse email n’apparaît pas, que ce soit dans un champ To: ou Cc:. Il reste cependant un problème: les messages issus de listes de diffusion ne contiennent généralement pas non plus l’adresse de chacun des destinataires. Il suffit de déplacer tout message, appartenant à une telle liste, vers un dossier qui lui aura été réservé à cet effet en définissant un filtre, pour chaque liste, qui recherchera l’adresse de celle-ci dans les champs To: ou Cc: où elle est généralement indiquée. Les règles de filtrage étant exécutées les unes à la suite des autres, il suffit d’indiquer la règle concernant les spams en dernière position.
3.3.3 – Filtrage sur le serveur
Avec les stratégies de filtrage à l’arrivée, les mes sages entiers sont transférés vers le poste de l’utilisateur avant d’être soumis au système de filtrage, ce qui n’entraîne aucune réduction du temps de connexion au serveur de messagerie. Cependant, le protocole POP3 permet de ne récupérer que l’entête d’un message, sans son corps. Or, puisque le règle de filtrage anti-spam est uniquement basée sur des champs de l’entête, il est possible de trier les messages directement sur le serveur et de récupérer seulement ceux qui sont dignes d’intérêt. On va présenter deux systèmes de filtrage.
Logiciel antispam
Le premier est basé sur des logiciels qui s’installent sur le poste de l’utilisateur et s’intercalent entre son logiciel de messagerie et son serveur POP3. Dans ce cas, les messages de spam, arrivent jusqu’à la boîte aux lettres de l’utilisateur, mais ils sont détruits avant que ce dernier n’en prenne connaissance. Il existe de nombreux logiciels anti-spam disponibles sous Windows ou Mac, et même sur Linux. Par exemple le SpamEater sous Windows, ou Mailfilter sous Linux.
Procmail
La seconde technique consiste à filtrer directement le courrier avant même qu’il soit stocké dans la boîte aux lettres. Ainsi, l’espace de stockage réservé aux nouveaux messages est préservé. Un exemple le plus utilisé est le Procmail (http://www.procmail.org). Il ne fonctionnent que sur Linux et ne peut être utilisé que si on dispose d’un accès interactif (via Telnet par exemple) à la compte utilisateur. Il est possible de trier les messages selon un très grand nombre de critères (n’importe quel champs de l’entête, taille du message, etc.) ou même de générer des réponses automatiques personnalisées.
3.3.4 – Spam, filtrage et conférences
Dans les conférences, nous allons retrouver les mêmes concepts que pour le courrier électronique, à savoir l’utilisation de systèmes de filtrage basée sur le contenu des entêtes des articles. Une différence importante avec l’email est que, d’une façon générale, un utilisateur consultant une conférence donnée ne récupère pas systématiquement tous les articles qu’elle contient avant de décider quels messages lui paraissent dignes d’intérêt, mais seulement leurs entêtes. Par conséquent, la mise en place d’un système de filtrage au niveau du logiciel permettant d’accéder aux conférences est particulièrement efficace puisqu’il n’a pas besoin de récupérer les articles en entier.
Les killfiles
Un killfiles est un fichier qui contient un certain nombre de règles de filtrage et qui est exploité par un logiciel de gestion de conférences. Sous Netscape Messenger ou Outlook Express, il est possible de créer les règles de filtrage. Par exemple, pour filtrer tous les articles ayant un sujet contenant les mots « Make MONEY FAST » ou « $$$ ». Si on utilise un logiciel de gestion de conférences sous Unix comme trn ou nn, on peut également créer des killfiles sous forme de fichiers texte.
NoCeM
NoCeM est un système puissant qui permet de définir des messages de contrôle spécifiques ayant pour effet de masquer certains articles considérés comme du spam par d’autres internautes. Le principe est le suivant: chaque utilisateur du logiciel a la possibilité de générer des messages de contrôle permettant, lorsqu’ils sont pris en compte par les autres utilisateurs, de masquer les articles leur faisant référence. NoCeM n’est actuellement disponible que pour des logiciels de gestion de conférences du monde Unix.
3.4 – Le retour du grand méchant spam
3.4.1 – Retrouver la trace du spammeur
l’envoi de message électronique se fait par l’intermédiaire d’un serveur de messagerie implémentant le protocole SMTP. Un spammeur qui désire envoyer un message de spam doit donc nécessairement disposer d’un accès au réseau et d’un serveur SMTP. Il y a trois techniques classiques que les spammeurs souvent utilisent: connexion direct au serveur SMTP du destinataire, l’utilisation d’un relais ouvert, et la falsification d’en tête. Dans les deux premiers cas, on peut facilement retrouver le serveur de messagerie ou l’adresse IP de l’expéditeur. Dans le dernier cas, il est beaucoup plus difficile à le faire. Une fois qu’on a trouvé l’origine du message de spam, comment ou peut réagir pour que les spammeurs ne puissent plus d’envoyer les spams.
3.4.2 – Accès du spammeur
Maintenant que nous avons identifier les points de connexion des spammeurs et les serveur de messagerie qu’il utilisent pour injecter leurs messages sur le réseau, découvrons comment déterminer la ou les personnes à contacter pour tenter de mettre en fin à leurs activité.
Il est parfois possible de trouver l’adresse recherchée en se rendant sur le site Web de la société concernée. Les fournisseurs d’accès Internet disposent presque toujours d’une charte d’utilisation appelée AUC (Acceptable Use Policy) qui interdit généralement à leurs clients d’envoyer du spam et que ceux-ci sont censés respecter sous peine de voir leurs compte fermés. En recherchant cette charte, on trouve souvent l’adresse qui permet de signaler les violations de celle-ci.
Un autre solution est d’écrire directement aux adresse postmaster@domaine des sites concernés, c’est à dire pointant vers la personne chargée de l’administration de la messagerie, d’après RFC822.
La dernière solution est peux être la plus simple. Elle consiste à utiliser le service http://www.abuse.net qui permet de retrouver l’adresse destinée à recevoir les plaintes concernant le spam. Mieux, on peut directement envoyer un message à l’adresse nom-dedomaine@abuse.net, le service se chargeant de le rerouter vers l’adresse de la mieux adaptée. Ex: un mail envoyé à uu.net@abuse.net sera en réalité transmis à l’adresse fraud@uu.net.
3.4.3 – Site Web du spammeur
L’obtention de la fermeture de l’accès Internet d’un spammeur est parfois efficace. Cependant, de nombreux spams font la promotion de services ou de produits proposés par l’intermédiaire d’un site Web. Si le site Web du spammeur a été créé chez un service d’hébergement gratuit tel que Geocities ou Xoom, il n’y a pas d’autre possibilité que de contacter l’équipe d’administration de celui- ci, en espérant qu’elle acceptera de fermer le site correspondant.
Si le spammeur possède son propre domaine (du type www.nomdomaine.com), nous disposons d’un outil: le service whois sur http://www.networksolutions.com/cgibin/whois/whois, qui renvoie un certain nombre d’informations sur un nom de domaine: son titulaire, les personnes chargées des questions administratives, techniques, etc.
Par exemple, le site Web du spammeur est www.handoi.com Registrant :
Tuan Nguyen Duc (GLJUPGFHBD) Waldschmidt str 20 Cham D-93413 DE Domain Name: HANDOI.COM Administrative Contact: Duc, Tuan Nguyen (IPLENRUGCI) 320076747709-0001@t-online.de Waldschmidt str 20 Cham D-93413 DE +49 9971 994767 Technical Contact: Xlink - Network Information Centre (HX-ORG) hostmaster@XLINK.NET Xlink - Network Information Centre Emmy-Noether-Str. 9 Karlsruhe, Karlsruhe DE +49 721 9652 330 fax: +49 721 9652 349 Record expires on 29-Nov-2003. Record created on 29-Nov-2002. Database last updated on 1-Jul-2003 13:14:06 EDT. Domain servers in listed order: NS1.WEBMAILER.DE 193.141.40.47 NS2.WEBMAILER.DE 194.120.12.252
On peut donc essayer d’envoyer un message aux contacts administratifs et techniques associés au domaine auquel le site Web appartient, tout en sachant que ces adresses mènent peut-être à la boite aux lettres du spammeur et que cale équivaudrait à lui répondre directement d’où le risque de recevoir encore plus de spam.
Si le contact technique semble provenir d’une autre société que celle titulaire du domaine, cela signifie sans doute que c’est cette société qui héberge le site Web en question.
3.4.4 – Traquer le spam dans les conférences
En effet, les spammeurs tentent également de brouiller leurs traces en falsifiant les entêtes et en utilisant des serveurs NNTP ouverts. La principale différence entre un article et un message électronique est la présence de champs spécifiques comme Newsgroups: qui joue le rôle du champ To:, Path: qui remplace les Received:, et NNTP-Posting-Host: qui indique le système à partie duquel l’article considéré a été envoyé.
Voici un exemple pour illustrer l’entête d’un article :
Subject: [PLANT] Aquatic Plant Cultivation Methods Newsgroups: rec.aquaria Xref: hallman.org rec.aquaria:56843 Path: hallman.org! ix.hallman.org! howland.reston.ans.net! news.cac.psu.edu! news.tc.cornell.edu! newsserver.sdsc.edu! nicnac.CSU.net! charnel.ecst.csuchico.edu! csusac! csus.edu! news.ucdavis.edu! landau.ucdavis.edu! jkelly! nntp.earthlink.net! usenet From: jkelly@landau.ucdavis.edu (Jim Kelly) Newsgroups: rec.aquaria Subject: [PLANT] Aquatic Plant Cultivation Methods Date: 10 Mar 1995 06:06:03 GMT Organization: University of California, Davis Lines: 641 Message-ID: <3joq8b$fe@mark.ucdavis.edu> NNTP-Posting-Host: landau.ucdavis.edu X-Newsreader: TIN [version 1.2 PL2]
Les champs From et Organisation: étant normalement définis par l’utilisateur. Le champ NNTP-Posting-Host indique l’article a été envoyé à partie d’un accès proposé par ucdavis.edu, En examinant le Path: de gauche à droite, on peut supposer que l’article a été injecté à partir d’un relais NNTP ouvert se trouvant sur la machine nntp.earthlink.net, mais il se peut aussi que le spammeur soit directement passé par un serveur de news proposé par news.ucdavis.edu, et que les sites indiqués ensuite aient été ajoutés par le spammeur pour faire croire qu’il a posté son message vie le serveur d’EarthLink. La réponse est d’interroger les administrateurs de news concernés.
En ce qui concerne les personnes à contacter, on peur donner les mêmes recommandations que pour le mail, tout en sachant que les adresses diffèrent parfois. Par exemple, les plaintes relatives aux articles de conférences émis vie le réseau ucdavis.edu doivent être envoyées à spam-complaint@ucdavis.edu au lieu de fraud@ucdavis.edu. D’une façon générale, on peut remplacer le postmaster par une adresse du type newsmaster@domaine ou news@domaine.
3.5 – Solutions pour administrateurs
Si le problème du spam peut être en grande partie résolu par l’utilisateur qui en est la victime, l’administrateur système peut également intervenir à leur niveau. On va présenter différente solutions techniques qui permettent de lutter contre le spam au niveau d’un site entier.
3.5.1 – Définir une politique d’utilisation
Une solution technique doit toujours être mise en oeuvre dans le respect d’une politique définir au préalable. Cette politique doit indiquer précisément les conditions d’utilisation acceptable des ressources du système d’information de l’entreprise, et les conséquences en cas de non-respect de celles-ci.
3.5.2 – Bloquer le spam entrant
Le premier objectif de tout administrateur qui souhaite lutter contre le spam va être de mettre en place des systèmes permettant de préserver ses utilisateurs de tels messages. On peut bloquer les spams à plusieurs niveaux: le routeur d’accès à l’Internet, les serveurs SMTP et NNTP, les serveurs Web.
Au niveau routeur d’accès
Presque tous les routeurs permettent aujourd’hui de définir des règles de filtrage au niveau IP par l’intermédiaire d’ACL (access list en anglais). Il est donc possible de définir de telles règles sur le routeur de façon à stopper un spammeur. Plusieurs stratégies peuvent être mises en place: bloquer tout une classe d’adresse appartenant à une entreprise ayant une activité de spam répétée, bloquer une seule machine ou uniquement le trafic SMTP issu d’un serveur précis. La dernière option permet l’accès à d’autre services tels que le Web ou le FTP, tandis que les deus autres empêcher toute connexion quel que soit son type. Si on a pas de possibilité de modifier la configuration du routeur, on peut également définir de telles règles au niveau du firewall.
Au niveau du serveur SMTP
Le blocage des spams au niveau du serveur de messagerie est très efficace.
- Sendmail:
Sendmail est le système de messagerie le plus célèbre au monde. Depuis la version 8.9, il intègre de nombreuses fonctionnalité contre le spam, parmi lesquelles le blocage de la transmission des messages reçus de l’extérieur n’étant pas à destination du domaine local (relais ouvert), le blocage du courrier comprenant une adresse de retour dont le domaine n’existe pas, le définition d’une liste d’adresse de messagerie, adresse IP ou domaines autorisés ou non, etc. - Procmail:
Procmail peut-être utilisé par l’administrateur qui peut créer des règles appliqués à un ensemble des utilisateurs.
Au niveau de serveur NNTP
Comme email électronique, il est possible de mettre en place des systèmes de blocage d’article de spam postés dans les conférences.
- Blocage des sites:
Il est possible de demander au serveur NNTP de refuser les articles provenant de certains serveurs connus pour diffuser des spams grâce à une technique appelée aliasing. Elle consiste à donner au serveur un alias correspondant au nom du site à bloquer. En effet, puisqu’un serveur n’accepte jamais d’article comportant un champ Path: ou son nom apparaît déjà, les articles émis par le site bloqué seront systématiquement ignorés par le serveur. - Contrôle d’accès
Contrôle d’accès à un serveur NNTP permet d’éviter qu’il soit utilisé pour poster des articles de spam à partir de sites non autorisés. Par exemple, on peur autoriser les sites du domaine spécifier à lire des articles seulement. - Utiliser NoCeM
Rappelons que NoCeM est un système qui permet de marquer des articles (spams) pour qu’ils n’apparaissent pas lors de la consultation d’une conférence. Au niveau du serveur NNTP, il existe une version de NoCeM, appelée NoCeM-on-spool, pui permet d’efface directement en local les articles correspondant aux avis reçus.
Le cas des accès distants
Nombre d’entreprises laissent leurs utilisateurs se connecter à distance à leurs ressources, notamment pour lire et envoyer du courrier électronique. Les utilisateurs à distance peuvent utiliser le serveur SMTP comme un relais serveur pour envoyer les messages. Une solution existe, demander à l’utilisateur distant d’établir une connexion POP3 avant de pouvoir utiliser le serveur SMTP.(POP-before_SMTP)
Bloquer les harversters Web (« spider »)
Les spammeurs utilisent des programmes spécialement conçu pour collecter les adresse email dans les Webs page. (ex: le spider WebZip). Une solution est de ne permettre que les navigateurs connus d’accéder à une adresse. Mais cette solution peut-être facilement passé par des logiciels qui peut feindre les navigateurs célèbres. Une autre solution, c’est mon expérience quand j’utilise le programme Webzip pour télécharger toutes les pages d’un site Web. Ce site utilise un mécanisme particulier pour lutter contre les spiders. Chaque page dans ce site contient un lien invisible pour les utilisateur, mais il est visible pour le programme spider. Une fois que le spider a extrait ce lien, il commence à télécharger la page à ce lien. Le Web serveur peut détecter que ce lien est demandé, alors il peut bloquer toute connexion à partir de l’adresse du spider.
3.5.3 – Bloquer le spam sortant
On peut facilement limiter le nombre de destinataire par une message à une vingtaine ou trentaine.
3.6 – Le spam et la loi
Lorsque les mesures techniques ne suffisent plus pour lutter contre un spammeur récalcitrant, il peut être nécessaire de porter l’affaire devant les tribunaux.
3.6.1 – Aux Etats Unis
Au niveau fédéral
De nombreuses discussions ont lieu depuis plusieurs années convenant du spam. Des dizaines de projets ont été proposés ou sont en cours d’examen auprès des instances législatives fédérales. Mais jusqu’à maintenant, aucune loi est été approuvée.
Au niveau des Etats
Dans de nombreux Etats, des projets de loi visant à interdire le spam ont été proposés et étudiés. Mais cependant les seuls textes adoptés se contentent d’obliger les spammeurs à indiquer des adresses réelles dans leurs messages.
3.6.2 – En France
Il n’existe aucune loi traitant explicitement du problème du spam. Cependant, certains textes sont susceptibles d’être applicables, en particulier dans le domaine de la protections des informations nominatives et de la lutte contre le piratage informatique.
4 – Trace sur Internet
L’importance liberté dont dispose tout internaute sur le Web peut lui laisser penser que son parcours, de site en site, est totalement anonyme et impossible à reconstituer par un tiers. En réalité, il n’en est rien : chaque consultation de serveur Web ; chaque page visualisée ; chaque clic sur un lien laisse non pas une mais plusieurs traces, aussi bien sur l’ordinateur de surfeur que sur les sites qu’il visite.
4.1 – Les traces locales
Intéressons nous tout d’abord aux traces laissées en local lors de la consultation d’un site Web à l’aide d’un logiciel de navigation. Chaque fois qu’on entre l’adresse d’un serveur dans la zone de saisie prévue à cet effet au sein du navigateur Web, cette adresse est automatiquement enregistrée sur votre disque dur, dans une liste des dernières adresses saisies.
Ensuite, dès qu’un page appartenant au site visité apparaît, la quasi totalité des fichiers qui la constituent est stockée dans un répertoire spécial appelé cache. Enfin, l’URL correspondant est inscrite dans un répertoire ou un fichier.
Si vous êtes la seule personne qui utilise l’ordinateur, tout ceci peut ne pas vous ennuyer. Mais si vous partagez votre machine ou que des tiers peuvent y accéder librement, que ce soit chez vous, dans un café Internet, et même sur la machine sur votre lieu de travail.
4.2 – Les traces à distance
Si les traces laissées en local sur le disque dur d’un internaute sont aussi nombreuses que précises, il ne faut pas pour autant oublier que le fait de surfer génère d’autres enregistrements, ailleurs que sur le poste client.
4.2.1 – Les fichiers log
Chaque Web serveur accédé dispose d’un ou plusieurs fichiers qui enregistrent de nombreuses informations relatives aux machines, logiciels de navigation et même individus accédant à n’importe quel document proposé sur le serveur. Ces fichiers, appelés fichier log, ont des objectifs origines sont tout à fait justifiables. En effet, ils permettent de définir des statistiques basées sur le fréquence de consultation de chaque fichier texte, image ou son proposé par le serveur , l’origine géographique des visiteurs, ou encore de mettre en lumière des erreurs involontaires, par exemple un lien vers un document inexistant au sein d’une certaine page Web ou script CGI qui plante.
Les fichiers log ont également pour objectif de faciliter la détection de certaines tentatives d’intrusion. En effet, ils sont généralement recoupés avec d’autres fichiers de ce type, permettant ainsi de bloquer temporairement ou définitivement l’accès au site à une ou plusieurs machines indélicates. Malheureusement, les informations que les fichiers logs contiennent peuvent être utilisées à des buts nettement moins justifiable, par exemple l’établissement de profils plus ou moins précis sur les visiteurs des sites Web considérés.
Voici un exemple de fichier log qui est récupéré à partir d’un serveur IIS 5, Windows 2000, le format de ce fichier est suit à la norme W3C Extended Log File Format :
#Software: Microsoft Internet Information Services 5.0 #Version: 1.0 #Date: 2003-07-08 04:34:35 #Fields: date time c-ip cs-username s-ip s-port cs-method cs-uristem cs-uri-query sc-status cs-version cs-host cs(User-Agent) cs (Referer) 2003-07-08 04:34:35 127.0.0.1 - 127.0.0.1 80 GET /iisstart.asp - 302 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) - 2003-07-08 04:34:35 127.0.0.1 - 127.0.0.1 80 GET /localstart.asp - 401 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) - 2003-07-08 04:34:35 127.0.0.1 - 127.0.0.1 80 GET /warning.gif - 304 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) http://localhost/localstart.asp 2003-07-08 04:34:35 127.0.0.1 - 127.0.0.1 80 GET /Web.gif - 304 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) http://localhost/localstart.asp 2003-07-08 04:34:35 127.0.0.1 - 127.0.0.1 80 GET /mmc.gif - 304 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) http://localhost/localstart.asp 2003-07-08 04:34:35 127.0.0.1 - 127.0.0.1 80 GET /help.gif - 304 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) http://localhost/localstart.asp 2003-07-08 04:34:35 127.0.0.1 - 127.0.0.1 80 GET /print.gif - 304 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) http://localhost/localstart.asp 2003-07-08 04:34:35 127.0.0.1 NGHIEMLONG\Administrator 127.0.0.1 80 GET /localstart.asp - 200 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) - 2003-07-08 04:34:35 127.0.0.1 NGHIEMLONG\Administrator 127.0.0.1 80 GET /win2000.gif - 304 HTTP/1.1 localhost Mozilla/4.0+ (compatible;+MSIE+5.5;+Windows+NT+5.0;+.NET+CLR+1.0.3705) http://localhost/localstart.asp
On peut voir dans le fichier la date, le temps, l’adresse IP, le port, l’URL, l’état, le Referer, et le navigateur utilisé, de chaque consultation dans le Web site.
4.2.2 – Comment effacer ces traces
Lorsque nous avons présenté les différentes traces laissées en local lors de la consultation de sites Web, nous avons pu proposer des solutions simples permettant de les effacer ou même d’en interdire la génération. Malheureusement, nous ne pouvons pas effacer les informations stockées sur des serveurs Web. La solution la plus efficace est d’utiliser un proxy.
Il s’agit d’un serveur qui sert d’intermédiaire entre le navigateur et les sites que vous consultez, et qui peut être utilisé pour masquer l’adresse dans les logs d’accès à un site Web. Ainsi, ce n’est plus l’adresse de l’internaute qui apparaîtra à chaque requête, mais celle du proxy, rendant l’identification plus difficile. On l’appelle le proxy anonyme.
Un proxy anonyme acceptent une adresse, et puis, il envoie une requête vers le serveur de destination. Après avoir reçu toutes les informations qui se contiennent dans la page demandée, le proxy les renvoie vers le navigateur du client. Alors dans le fichier log du serveur de destination, on ne peut trouver que les informations concernant le proxy.
4.2.3 – En quoi toutes ces traces peuvent-elles être dangereuses
Nous avons vu jusqu’à maintenant qu’un administrateur de site Web pouvait disposer des informations suivantes:
- Nom et l’adresse de la machine de l’utilisateur
- Date et heure d’accès
- Fichiers consultés
- Identification éventuelle de l’utilisateur
- Page à partir de laquelle chaque fichier à été appelé
- Type et version du logiciel de navigation utilisé
- type et version du système d’exploitation
- Type d’architecture matérielle
Il faut en ajouter d’autres, par exemple les cookies, les adresses email obtenues à partir des accès anonymes à un serveur FTP proposé en complément un site Web, les réponses données par un utilisateur à un formulaire.
La question est: en quoi ces informations peuvent-elles être dangereuses, en termes de respect de la vie privée?
Tout d’abord, rappelons que si les informations qui peuvent être obtenues par un administrateur de site Web sont relativement précisées, elles ne permettent pas, dans la majorité des cas, de retrouver l’identité des personnes qui les ont générées. Au mieux, on peut savoir dans quel pays, voire dans quelle ville, se situe la personne (cas d’un fournisseur d’accès Internet) ou dans quelle société elle travaille.
Cependant, en cas de collaboration des différents intermédiaires (dans le cadre d’une enquête de police par exemple), il va sans dire que tout fournisseur pourra recouper ses propres logs avec ceux d’un administrateur de site Web afin de déterminer l’identité précise d’une personne ayant accédé à un certain service, à un certain moment. Il en est de même pour les fichiers log générés lors de l’accès à l’Internet au sein d’une entreprise. Mais sauf en cas de crimes ou délits, el est rare qu’on arrive à de tels extrêmes.
En revanche, il est beaucoup plus fréquent que l’on soit amené à remplir un formulaire en ligne dans le cadre d’une commande, d’un demande de renseignements, de la participation à un jeu. Il est alors facile pour l’administrateur d’un site Web de savoir qui vous êtes à partir du moment où vous avez remplir un tel formulaire, tout au moins jusqu’à ce que vous quittez le site en question.
Il est exact que cela ne permettre pas de vous identifier systématiquement lors de vos prochaines visites, puisque l’adresse qui vous est allouée à chaque connexion au réseau via un fournisseur d’accès est différente. (mais cookie alors ?)
Rares sont les techniques qui ont fait autant de bruit que les cookies. Les cookies ont mauvaise réputation alors que leurs objectives initiaux n’avaient pourtant rien de bien réprimandable.
Tout a commencé à partir d’un constat: le protocole HTTP est un protocole sans état. Ce caractéristique sans état complique le mise en place de certains services qui nécessitent justement de conserver l’historique d’une session. On peut donner un exemple: Imaginons qu’un client se connecte à un site marchand, vie l’Internet. Ce client va être amené, à moment ou un autre, à sélectionner un ou plusieurs articles au sein d’une même commande. S’il pouvait en choisir un seul à la fois, ce la ne poserait pas beaucoup de problème. Mais la fois prochaine s’il souhaite commander plus d’un article, comment le serveur peut-il mémoriser la liste de ces différents articles.
Au milieu des années 1990, Lou Montulli, employée chez Netscape, écrivait une spécification qui présentait une solution simple permettant à une application exécutée sur un site Web (un programme CGI) de stocker et de rapatrier des informations sur le logiciel client. L’objectif était donc de permettre l’enregistrement d’un certain nombre d’information, pour le compte d’un serveur, au sein d’un navigateur Web de façon à pouvoir identifier de façon unique les requêtes successives envoyées par un même client. Les cookies étaient nés.
Le société Netscape propose sur son site Web la spécification originale des cookies sur laquelle on va base notre étude. Mais il faut attendre jusqu’en 1997 quand la RFC 2109 était adoptée par Netscape et Microsoft, les cookies sont acceptés officiellement.
5.2.1 – Principes généraux
Un cookie est une information envoyée par le serveur à un client Web qui doit la garder en mémoire. Lorsque certaines conditions sont réunies, un cookie stocké à côté client peut être renvoyé au serveur l’ayant positionné, voire à d’autre serveur. Ainsi, la transmission de cookies, entre clients et serveurs, permet d’ajouter une certaine persistance de l’information dans le cadre des transactions Web. Concrètement, deux nouveaux entêtes HTTP ont été ajoutés: Set-cookies: et Cookie:
Le premier est inséré dans l’entête d’une réponse envoyée par un serveur à un client. Il permet de positionner un cookie à côté client. Le second fait l’opération inverse, cad qu’il donne la possibilité à un navigateur d’inclure la valeur d’un cookie dans l’entête d’une requête HTTP envoyé à un serveur.
5.2.2 – Positionnement et accès
Set-cookie:
Cet entête permet à un serveur de positionner un cookie. Il a la syntaxe suivante :
Set-cookie: Nom=valeur; expires=DATE, domain=DOMAINE; path=CHEMIN; secure
Le premier champ qui apparaît dans cet entête est le nom du cookie suivi de la valeur qui lui est associée. C’est le seul argument qui doit obligatoirement figurer dans tout entête Set-Cookie.
Le champs expires indique une date d’expiration optionnelle pour le cookie. Lorsque aucune date d’expiration n’est précisée, le cookie ne doit pas être stocké sur le disque de l’utilisateur et il est détruit dès que celui-ci ferme son navigateur.
Si le troisième argument, domain, n’est pas spécifié, le cookie ainsi positionné n’est accessible qu’au serveur qui l’a généré. Pour permettre l’accès à un cookie à d’autres serveurs appartenant à un même domaine, on peut indiquer un nom de domaine via ce champ. Ainsi, si on définit .netscape.com comme nom de domaine, toutes les machines du type www.netscape.com, home.netscape.com ….pourront lire la valeur du cookie.
Le champ path=, permet de préciser le préfixe des URL aux quels le cookie s’applique. Par exemple, si on indique path=/doc, le cookie ne sera renvoyé qu’au sien des requêtes accédant à des fichiers dont l’URL débute par /doc, soit /document/, /docs/index.html etc. si on souhaite que le cookie s’applique à toutes les pages d’un site. Il suffit de spécifier path=/. Lorsque cet argument est omis, le champ path prend comme valeur de l’URL de la réponse qui l’a positionner.
Le champ secure est un mot clé qui ne prend pas de valeur. Lorsqu’il est positionné, la valeur du cookie ne sera renvoyée que si la connexion entre le client et le serveur est sécurisée, cad établie via SSL.
Exemple: Un champs Set-cookie du site www.google.com
Set-Cookie: PREF=ID=3c4aecce6751a44a: TM=1058521363:LM=1058521364: S=cMCf84Q9Hv-YNr_N; ·expires=Sun,·17-Jan-2038·19:14:07·GMT; ·path=/; ·domain=.google.com
Cookie:
Cet entête permet au navigateur de renvoyer à un serveur un ou plusieurs cookies qui ont été positionné auparavant, il a la syntaxe suivante.
Cookie: nom1=valeur1; nom2=valeur2; ...
Ainsi, plusieurs cookies peuvent être envoyés dans le même entête Cookie: d’une requête HTTP, s’ils sont susceptible de répondre à certaines conditions.
Règle d’accès
Les cookies stockés par un client Web ne sont pas automatiquement et systématiquement renvoyés aux serveurs consultés par l’utilisateur. Un certain nombre de règles, que nous allons présenter maintenant, doivent en effet être respectées. A chaque requête émise, le navigateur va vérifier s’il dispose d’un cookie susceptible d’être renvoyé au site auquel il est connecté. Pour le faire, il va tout d’abord vérifier la concordance entre le nom du site Web et la liste de tous les cookies dont il dispose. Rappelons que deux cas peuvent se présenter: soit le cookie est associé au nom exact du site considéré, soit il est associé à un nom de domaine qui correspond à celui du site en question.
Ensuite, s’il existe au moins un cookie répondant à la condition précédente, le navigateur examine l’URL contenue dans la requête HTTP et vérifie qu’elle coïncide avec celle spécifiée pour le cookie (valeur du champ path:)
Enfin, si les deux conditions sont validées, le cookie est envoyé dans la requête à moins que sa date d’expiration n’ait été atteindre, auquel cas il est automatiquement détruit. Il est possible que plusieurs cookies soient envoyés simultanément durant une même requête. Si c’est le cas, les cookies sont spécifiés dans l’entête Cookie: de telle façon que ceux qui s’appliquent aux chemins les plus précis soient indiqués en premier. Ainsi, un cookie ayant une valeur path=/ sera indiqué en fin de la liste.
Ex: le cookie « nom1=foo » avec le chemin « / » est envoyé avant le cookie « nom1=foo2 » avec le chemin « /bar ».
Si un script CGI veut supprimer un cookie, il doit positionner un cookie avec le même nom, et le champ expire est dans le passé. Le chemin doit être correspondant.
5.2.3 – Limitation de stockage
D’après la spécification de Netscape, un navigateur doit d’accepter et de garder en mémoire :
- Un total de 300 cookies
- 4K octets par cookie
- 20 cookies par domaine
- 20 cookie par serveur.
Bien que ces spécifications soient des valeurs minimales, un serveur ne doit pas d’attendre à ce qu’un navigateur puisse dépasser ces limites. Lorsque les valeurs de 300 cookies au total et 20 cookies par domaine ou serveur sont atteintes, le navigateur doit effacer les cookies les plus anciennement accédés.
Les cookies ont de nombreuses utilisations parfaitement défendables : En voici quelques unes :
Prise de commandes
Sans utilisation des cookies, il est possible que le conception de l’application de prise de
commande en ligne aurait été plus complexe : En tout cas, il n’aurait pas été possible de
retrouver la fiche du client lors d’une nouvelle commande, à moins de lui demander de
s’identifier de nouveau via un nom d’utilisateur associé à un mot de passe.
Accès personnalité
Une autre utilisation fréquemment rencontrée dans le monde des cookies est la possibilité donnée à un internaute de paramétrer de façon personnalisée la page d’accueil d’un site Web. Si nous prenons l’exemple d’un site d’information, il est de plus en plus fréquent que l’utilisateur puisse définir des centres d’intérêt de façon que le serveur ne lui présente que les menus susceptibles de l’intéresser. En stockant un identifiant dans un cookie, le serveur peut savoir automatiquement quelles rubriques affichés à l’écran. Ce principe peut être employé pour tout autre type de service nécessitant d’identification de l’utilisateur.
Rotation de publicité
De plus en plus des sites Web incorporent de la publicité au sein des pages qu’ils proposent, de façon à fiancer une partie des coûts engendrés par des sites toujours plus riches et travaillés. Cependant, les visiteurs de ce type de site risquent d’être quelque peu lassés de voir toujours la même publicité sur les différentes pages qu’ils consultent.
Identifier un navigateur
En réalité, tout n’est pas aussi simple. La première constatation que l’on peut faire est que certaines applications des cookies permettent de vous identifier d’une session à l’autre. Ou, plus précisément, d’identifier votre navigateur votre navigateur au fil de vos consultations d’une même serveur. Au minimum, un administrateur de site Web pourra savoir qu’une même personne, via son navigateur, est venus un certain nombre de fois sur son site et connaître précisément la liste des documents consultés. Sans la présence de cookie, il n’aurait pu suivre qu’une session et n’aurait pas été capable de « connaître » la personne par la suite.
Identifier un individu sur un site
Identifier une personne ne veut pas forcément dire qui elle est. En revanche, si cette même personne est amenée à révéler son identité en remplissant un formulaire, l’administrateur du site Web considéré va non seulement savoir qui consulte son site à partir du moment où l’internaute a donné des informations personnelles le concernant mais, pire, il va pouvoir le reconnaître par la suite et savoir, à chaque visite, quels documents il aura consultés.
Traquer un individu sur plusieurs sites
Il est cependant possible d’aller encore plus loin. On a parlé de publicités utilisant des cookies afin de ne pas toujours présenter la même annonce à une même personne, via l’utilisation d’un identifiant unique. Ceci ne pose pas de problème particulier lorsque c’est la même société qui gère la publicité sur son ou ses sites Web. Mais que se passe-t-il si une société externe, spécialisée dans la publicité en ligne, a la possibilité d’insérer des publicités sur de très nombreux sites Web de par le monde, lui permettant ainsi de savoir précisément le parcours d’un même internaute parmi ces différents sites. En exemple typique est l’entreprise DoubleClick (www.doubleclick.com) et ses célèbres cookies.
Cookies et DoubleClick
Dans les pages d’un site du client du DoubleClick, DoubleClick insère un publicité sous la forme d’une image. Mais au lieu que ces publicités soient stockées sur les sites Web en question, elle sont stockées sur les serveurs spécialisés de la société DoubleClick.
Ainsi, lorsqu’un navigateur va récupérer les différents éléments constituant une page Web de ce type, il va également envoyer en enquête vers DoubleClick permettant d’afficher les images de publicité. Avec le champ Referer: de l’entête HTTP de la requête, DoubleClick peut savoir facilement à partir de quelle page de quel serveur HTTP sa publicité est visualisée. Mais avec cela, DoubleClick ne peut pas identifier qui demande chacune de ces publicités. C’est là que les cookies entrent dans le jeu: il suffit de placer un cookie dans les réponses de façon à positionner un identifiant unique. Ce cookie a été placé dans le disque de l’internaute la première fois que cet internaute consultait une page qui contient la publicité de DoubleClick.
Cet technique permet de ne pas afficher la même publicité plusieurs fois à la même personne, même si elle visite plusieurs sites différentes. En outre, il est possible de proposer des annones en relation avec le type des sites visités par l’internaute.
Heureusement les navigateurs actuels permettent les utilisateurs la possibilité de contrôle total sur les cookies. Les utilisateurs peuvent accepter ou refuser tous les cookies installés par les serveurs. Ils peuvent aussi accepter ou refuser un cookie d’un site Web particulier. Ces options sont possibles dans Internet Explorer et Netscape Navigator, deux navigateurs les plus populaires.
On va ainsi voir que l’exploitation de certaines faibles, connues principalement des hackers et des spécialistes en sécurité, va permettre non seulement de découvrir l’identité réelle mais également de faire planter l’ordinateur à distance, d’accéder au contenu de n’importe lequel des fichiers ou encore de faire croire que vous passez une commande sur votre site de commerce électronique préféré alors qu’en réalité vous être en train de révéler à un pirate des informations aussi sensibles que vos coordonnées bancaires.
Pour le faire, nombres d’attaques reposent sur l’exploitation de faibles de sécurité au sein des logiciels de navigation du marché, et particulier au niveau des technologies actives de Web, comme Java, Javascript, ActiveX … Ces technologies permettent d’exécuter des scripts ou programmes directement sur l’ordinateur de l’internaute, avec les risques que cela comporte pour ce dernier.
6.1.1 – Data-driven attaque
Il est possible pour les crackers de placer de mauvaises données dans des bonnes applications pour obtenir des résultats indésirables.
Supposons qu’un utilisateur a configuré Microsoft Word pour maintenir les fichiers qui a l’extension .doc dans son navigateur Internet Explorer. Quand il télécharge un fichier .doc particulier, son ordinateur peut être infecté par le virus macro. Ce type d’attaque s’appelle data-driven attaque, car la nature de l’attaque est déterminée par des données qui sont téléchargées. La plupart des attaques sur l’Internet sont des attaques qui se reposent sur des données malicieuses téléchargées.
On va examiner quelques attaques variés de ce type.
Social Engineering
Le « Social Engineering », en français est « subversion psychologique », est un des attaques les plus simples et les plus efficaces consiste à donner un message demandant à l’utilisateur lui faire quelque chose dangereuse. Ces attaques sont efficaces parce que la plupart des utilisateurs sont conditionnés pour suivre quoi que les instructions apparaissent sur l’écran. Voici quelques types de message qu’un attaquants pourrait souhaiter montrer sur un écran de l’utilisateur:
- Il y a un problème avec votre compte. Veuillez changer votre mot de passe à NowSafe et attendre les instructions suivantes.
- Il y a un problème avec votre compte et nous sommes incapables pour facturer votre carte de crédit. Entrez votre numéro de carte de crédit et la date d’expiration dans les espaces au dessous de et cliquez sur le bouton Submit.
- Nous avons détecté que vous utilisez une ancienne version du navigateur Web. Veuillez cliquer sur ce URL pour télécharger une nouvelle version du logiciel, alors exécuter le programme appelé Setup.exe pour l’installer.
Quelque extension du Web, comme Javascript, permet de faciliter l’apparence des messages sur l’écran de l’utilisateur. Il n’y a aucune bonne solution pour des sociales attaques autres que l’éducation.
Exploitation des bugs des navigateurs
Les navigateurs ont des bugs. Quelques bugs des navigateurs dépendent des données. Un attaquant qui connaît ces bugs peut faire le navigateur change ses comportements prévus. La manière la plus commune pour un navigateur à l’échouer est pour qu’elle se brise. Sur un ordinateur sans protection de mémoire, un accident de navigateur peut faire planter l’ordinateur, crée une attaque efficace de déni de service. Par exemple, un bug que nous connaissons environ dans le moteur de disposition de HTML de Netscape Navigator pourrait être exploité dans les versions de Netscape Navigator 1, 2, et 3. Le bug faire le Netscape Navigator alloue des gigaoctets de mémoire, faisant briser le navigateur sur chaque plateforme. Sur quelques plateformes, la tentative par Navigator d’assigner de grandes quantités de mémoire a fait planter l’ordinateur entier.
Dans les nouveaux navigateurs comme Internet Explorer, ou Netscape Navigator, il y a plain de bugs qu’on peut utiliser pour faire les planter. Par exemple, dans Netscape Navigator 4.x, si on met un lien « mailto: email email …. » dont email est une vraie adresse email. L’attaque consiste à indiquer plusieurs adresse fictives au sein de ce champ, obligeant le logiciel de messagerie à envoyer un même message à différentes personnes.
6.2 – Les langages de programmation Web
Les langages de programmation Web comme Java ou Javascript peuvent être utilisés pour attaquer les internautes. Java et Javascript sont des langages utilisés pour ajouter l’interactive à des pages Web. Tandis que les deux langages apparaissent similaire, ils sont deux langages totalement différents avec les sémantiques différentes, les mécanismes de sécurité différents, et les communautés des utilisateurs différentes.
6.2.1 – Java
Java est un langage orienté objet moderne qui a une syntaxe semblable à C++, la collection d’ordures automatique, et avoir un modèle simple d’inhérence. Bien que Java ait été en grande partie favorisé comme langage pour le World Wide Web, Java est en fait un langage de programmation universel qui peut être employé pour développer n’importe quel programme simple d’un application de cinq lignes aux applications compliquées.
La machine virtuelle de Java (JVM) peut exécuter des programmes de Java directement sur un système d’exploitation tel que Windows ou Linux, alternativement, la JVM peut être embarquée à l’intérieur d’un navigateur Web, permettant à des programmes d’être exécutés pendant qu’ils sont téléchargés du World Wide Web.
La sûreté de Java
Les inventeurs de Java ont supprimé plusieurs caractéristiques de Java pour augmenter la sûreté de Java.
- Au lieu de permettre aux programmeurs de gérer la mémoire avec new et delete, Java a un collecteur d’ordures automatique.
- Java peut vérifier la taille des tableaux et des chaînes de caractère. Ce sont le source majeur des fautes de C et C++.
- Java n’a pas de pointer.
- Le contrôle de type de Java est fort.
- Java a un système de contrôle des exceptions sophistiqué
Avec ces caractéristiques, Java devient un langage de programmation sûr. Mais la sûreté n’est pas sécurisée.
La sécurité de Java
Java utilise des techniques variées à limiter les choses qu’un programme téléchargé peut faire. Ils sont Java sandbox, la classe SecurityManager, le ByteCode Verifier, et le Java Class Loader.
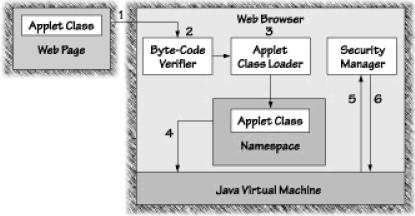
- Sandbox
Le modèle de sécurité original fournit par la plate-forme Java est connu sous le nom de sandbox. Pour les Java programme, il est interdit de manipuler directement un device de l’ordinateur ou faire une appelle directement au système d’exploitation. En effet, les programmes Java s’exécutent dans un espace virtuel bordé, c’est le sandbox. - Classe SecurityManager
If tout programme Java est interdit, alors ils ne peuvent pas envoyer les informations sur le réseau, ne peuvent pas lire ou écrire les fichiers sur le disque dur, cela très sécurisé. Mais ces limitations font Java devient monotone, car il n’y a pas beaucoup de choses intéressantes que Java peut faire. Java utilise une série de classe qui permet les programmes de s’exécutant dans le Sandbox peuvent communiquer avec le monde dehors. Par exemple, la classe FileOutputStream nous permet d’ouvrir un fichier pour l’écriture sur le disque dur. Normalement, java considère que les programmes téléchargés à partir d’un source incroyable (untrusted), comme Internet, doivent s’exécuter avec moins privilège que les programmes qui s’exécutent directement à partir du disque dur (avoir l’accès total – trusted). La SecurityManager est une classe spéciale, elle détermine si une opération peut être autorisée ou non. - Classe Loader
La Classe Loader permet de charger dynamiquement du code sur une machine. Ce code peut provenir du disque dur ou du réseau. Tous les objets Java étant des classes, le class loader détermine quand et comment des classes peuvent être ajoutées à l’environnement d’exécution Java. - ByteCode Verifier
Lorsqu’un programme Java est compilé, il est transformé en byte-code. Afin de s’assurer de l’innocuité de ce code envers le système de l’utilisateur, on fait appel au vérificateur de byte-code.
Applet signé et certificat
Par défaut, un applet est « untrusted ». Pour qu’il puisse être autorisé, par exemple à écrire sur le disque dur, le concepteur va devoir signer son applet de façon à identifier sa provenance. Ensuite les utilisateurs souhaitant exécuter cet applet devront se procurer le certificat permettant d’identifier sa signature et ainsi autoriser l’applet à fonctionner correctement. Les applets signés en utilisant un certificat (Certificat des publisheur de logiciel) peuvent s’exécuter sur la machine du client avec le privilège total.
Le problème de sécurité de Java
- Erreur d’implémentation de Java. La plupart des bugs dans Java sont des bugs d’implémentation, qui sont facilement trouvés et fixés. Il y a trois types principaux :
- Bug dans la Java Virtual Machine qui permettent à un programme de violer le système de type de Java. Il est possible d’exécuter des codes de machine facultatifs.
- Les bugs des librairies de classe, qui permettent les programmes d’accéder à des informations privées.
- Les bugs dans la conception de Java Le bug le plus sérieux ici c’est que le modèle de sécurité de Java n’est jamais formalisé. Le groupe Princeton Secure Internet Programming a trouvé que beaucoup de problèmes existe car il n’y a pas de modèle de sécurité formel dans Java. Le deuxième problème principal avec la sécurité de Java est que la sécurité du système entier dépend du système de contrôle de type du Java, et ce système dépend de la classe SecurityManager et de ByteCode Vérifier. Dans Java, les codes validés sont des codes qui se sont passés la barrière de ByteCode Vérifier.
- Le bug dans la politique de Java DNS
Un applet téléchargé ne peut que initier des connexions à la même machine à partir de laquelle il est téléchargé. Mais le mot «la même machine », il signifie quoi? Sun dit que : « la même machine » signifie n’importe quelle machine qui a le même nom de DNS avec l’ordinateur à partir de lequel l’applet est téléchargé. Plusieurs ordinateurs sur l’Internet ont plus qu’une adresse IP pour un seul hostname. Les différentes IP adresses peuvent être utilisées pour les interfaces différentes. Un nombre quelconque d’ordinateur peuvent être assignés une seul nom car ils fonctionnent comme un seul serveur de DNS (DNS round robin). Nombreux serveurs mais chacun a sa propre adresse IP. Alors un applet peut ouvrir la connexion avec plusieurs machines sur l’Internet. Si un attaquant peut convaincre un serveur de DNS A, il peut faire réorienter les requêtes vers le serveur A vers le serveur avec l’adresse xxx.xxx.xxx.xxx quelconque de l’attaquant.
6.2.2 – Javascript
Javascript est un langage de programmation développé par Netscape pour ajouter des animations et les interactions dans les pages Web. Les programmes de Javascript résident dans des fichiers de HTML. Il peut commande le navigateur: un programme Javascript peut créer des nouvelles fenêtres, entrer des textes dans des champs d’une forme, sauter à un autre URL, changer le contenu d’un document HTML lui-même, calculer les fonctions arithmétiques.. etc.
Javascript est le langage original du Netscape Navigator. Pour la raison Javascript a plusieurs fonctions spéciales conçues à modifier l’apparence du navigateur. Tandis que Javascript est appelé « scripting langage », mais il est vraiment un langage à but général comme les autre langages de programmation.
La sécurité de javascript
Un programme Javascript doit avoir plus sécurité que les programmes écrits en Java ou les autres langages de programmation pour les raisons suivantes :
- Il n’y a aucune méthode à côté client de Javascript pour accéder directement au système du fichier à côté client.
- Il n’y a aucune méthode de Javascript pour ouvrir directement des connexions à d’autres ordinateurs sur le réseau.
Mais Javascript, comme les autres parties du Web, est entrain de changer. Maintenant, Javascript a beaucoup de capacités d’accéder à la machine du client, mais dans le contrôle. Les problèmes de Javascript peuvent être divisés en deux types principaux: attaque Déni de Service (Dénial of Service) et la violence de l’intimité.
- Javascript et la gestion de ressource
- Javascript peut être employé pour effectuer des attaques efficaces de déni de service contre les utilisateurs des navigateurs Web. Ces attaques peuvent être résidentes dans les pages Web elles peuvent être envoyées aux utilisateurs qui utilisent les logiciels de messagerie qui comprend Javascript dans le courrier électronique.
- Javascript et l’intimité
Lorsque Javascript s’exécute dans le navigateur, les ressources que le navigateur possède peuvent être accédés par les morceaux de Javascript. Les anciennes implémentations de javaScript ont des variés problèmes qui peuvent faire perdre la confidentialité et l’intimité des utilisateurs :- Javascript pourrait être employé pour créer les formes qui se sont automatiquement soumises par email. Ce mécanisme pourrait être employés pour collecter les adresses d’email des personnes visitant un page Web.
- Un programme Javascript a l’accès à l’histoire des navigateurs. Il permet un site Web de déterminer tous les URLs que l’utilisateur a visité.
- Un programme Javascript qui marche dans une fenêtre peut surveiller les URLs des pages visités dans des autres fenêtre.
Ces problèmes tous ont été corrigés dans de plus nouvelles versions de Netscape Navigator. Monsieur Eric Greenberg de Netscape indique que la vraie raison de la perte d’intimité n’est pas que le Javascript a accès à l’information sensible, mais que cette information peut partir d’ordinateur de l’utilisateur.
6.2.3 – VBScript de Microsoft Internet Explorer (IE)
VBScript est le langage de Microsoft Internet Explorer , le navigateur est utilisé beaucoup par les utilisateurs normaux. Les programmeurs peuvent choisir VBScript ou Javascript pour programmer à côté client. VBScript est intégré dans IE pour que IE puisse bien travailler avec les technologies de Microsoft sous Windows comme COM (Component Object Model) et ActiveX. Comme Javascript, VBScript a aussi des sérieux bugs qui peuvent être exploités par les attaquant. Par exemple, des nombreux problèmes de sécurité avec la fonction GetObject par Georgi Guninski. Cette fonction permet de créer un objet ActiveX dans l’environnement de IE. Jusqu’a la version 6.x de IE, des bugs de la fonction GetObject existent encore. Ces bugs permettent aux script VBScript de lire le contenu des fichiers sur le disque dur.
6.2.4 – Les attaques
Attaque de déni de service (DoS)
Un problème significatif de sécurité de Java et de Javascript est la difficulté d’empêchement des attaques déni de service. Une attaque de déni de service est une attaque dans laquelle un utilisateur (ou un programme) prend tellement d’une ressource partagée que rien la ressource est laissée pour d’autres utilisateurs ou usages.
N’importe quel langage de programmation ou environnement qui permet d’allouer des ressources au niveau système, et il n’y a aucune limitation de cette ressource, est le sujet des attaques déni de service. Java et Javascript apparaissent être spécialement sensibles pour eux. Des programmes Java ou Javascript peuvent facilement allouer plain de ressource, et il est difficile pour les utilisateurs à défendre contre ce type d’attaque.
Les types d’attaque de déni de service
Attaque sur le CPU et la pile
Un programme Java ou Javascript peut accabler un ordinateur en demandant trop de ressources de CPU ou de mémoire. Par exemple, une fonction Java ci-dessous :
public int fibonacci(int n)
{
if (n>1)
return fibonacci(n-1)+fibonacci(n-2);
if(n=>0)
return 0;
return 1;
}
fibonacci(1000000);
Et un morceau de code de Javascript correspondant :
<html>
<body>
<script>
function fibonacci(n)
{
if(n>1)
return fibonacci(n-1)+fibonacci(n-2);
if(n>=0)
return 0;
return 1;
}
for(i=0;i<100000;i++)
{
document.write("Fibonacci number "+i+" is "+fibonacci(i) +"<br>");
}
</script>
</body>
</html>
Les navigateurs différents ont des façons différentes pour terminer les programmes Javascript. Netscape Navigator affiche un message qui demande l’utilisateur de terminer ou laisser le script lent marche. Mais quelque version de Internet Explorer termine la fonction Fibonacci avec une erreur de débordement de pile. En exécutant ce script, le navigateur ne peut rien faire.
Avec une boucle très simple, on peut planter un navigateur, même c’est un navigateur moderne comme Mozilla :
<html>
<head>
<title>Demonstration de déni de service</title>
</head>
<body>
<script>
while (1)
{
alert("Ici est un message de Javascript");
}
</script>
</body>
Attaque d’échange de l’espace :
public mouseDown(Event evt, int x, int y)
{
String str="Cette chaîne est longue.";
int i;
for(i=0;i<1000000;i++)
{
str = str+str;
}
return true;
}
Lorsqu’on exécute ce script, les deux Internet Explorer et Netscape Navigator essayent d’allouer des grands sommes de mémoire. Ce type d’attaque nuit au navigateur et même les autres applications qui marchent dans l’ordinateur, car l’ordinateur doit échanger, échanger et échanger les zones de mémoire. Dans cette attaque, le disque dur est totalement occupé, et il ne peut rien faire autrement, et le CPU est effectivement bloqué.
Attaque sur le système de gestion de fenêtre
Java et Javascript permettent des codes téléchargés de créer et contrôler les fenêtres sur la machine de l’utilisateur. Les opérations de l’Interface Graphique d’Utilisateur (GUI) consomment une quantité énorme de ressources de système dans les machines. En créant plusieurs fenêtres, la performance du système entier doit diminuer significativement.
Il est trop difficile pour les utilisateurs à contre les attaques de déni de service, car la plupart des attaques de déni de service est le résultat des bugs de programmation, des architectures des langages de programmation.
Les attaques de proofing
La combinaison de Java et Javascript peut être employée pour confondre l’utilisateur. La conséquence est qu’un utilisateur faisant une erreur et fournissant des informations sécurisées à une partie fausse.
- Truquer nom d’utilisateur et mot de passe avec Java
- Quand un applet « untrusted » crée une fenêtre, la plupart des browsers d’enchaînement marquent la fenêtre d’une façon quelconque de sorte que l’utilisateur sache que ce n’est pas secure. Mais si un applet marche dans une fenêtre, aucune étiquette est affichée. Une page HTML peut afficher un beau fond et utilise un applet Java pour créer un panneau nom d’utilisateur/mot de passe. Comment les utilisateur vont réagir à la situation.
- Truquer le bar d’état avec Javascript
Beaucoup d’utilisateurs exécutent n’importe quel programme qu’ils ont téléchargé d’un domaine bienfait confiance. Cependant, il y a beaucoup de manières de faire le Web browser d’un utilisateur télécharge un programme d’un domaine X mais montrer les sélections visuelles qui indiquent le programme en fait est téléchargé à partir des autres domaines. Par exemple, l’utilisateur peut voir que un programme nommé setup.exe à l’URL www.microsoft.com/xxx/xxx/xxx/setup.exe mais en réalité, il est à l’URL www.hackerspace.com/xxx/xxx/setup.exe.Javascript a plusieurs outils qui peuvent être utilisés pour truquer le contexte d’utilisateur :
-
Javascript peut afficher des boîte contenant n’importe quel texte.
-
Javascript peut changer le contenu du bar d’état du navigateur
-
6.3 – Les codes de machine téléchargés avec ActiveX et les plug-ins
Une des choses les plus dangereuses que vous pouvez faire avec un ordinateur qui est relié à l’Internet doit télécharger un programme et l’exécuter. Car un programme s’exécute dans l’environnement des systèmes d’exploitation n’a aucune limitation d’accès aux ressources. Quand on télécharge un programme et l’exécute, on a placé soi-même entièrement dans les mains de l’auteur du programme. Quelques programmes peuvent supprimer les fichiers dans le disque dur ou envoyer les informations collectées vers un serveur sur l’Internet.
Le but d’un attaquant est d’exécuter un programme dans l’ordinateur d’un internaute sans sa connaissance. Une fois que cela est fait, les autres attaques sont possibles. La manière la plus facile pour qu’un attaquant accomplisse ce but est donner ou télécharger un programme à la machine de l’utilisateur. Même les système d’exploitation sécurisés avec la protection de mémoire et d’autres mécanismes de sécurité, tels que Windows NT et UNIX, n’offrent à des utilisateurs aucune vraie sécurité contre les programmes qu’ils téléchargent et exécutent, car quand un programme qui marche, il hérite de tous les privilèges et droits d’accès de l’utilisateur qui l’a appelé.
6.3.1 – Plugins de Netscape
Les plugins de Netscape Navigator sont des programmes qui étendent la capacité du Navigator. Les plugins ont été présentés avec Netscape Navigator comme façon simple pour étendre le navigateur avec des autres programmes exécutables qui sont écrits par des entreprises et sont chargés directement dans le navigateur. Au lieu de télécharger des données et les sauvegarder dans un fichier, et traiter le fichier avec une application correspondante, les données peuvent rester dans l’espace de mémoire du navigateur et sont traitées directement par le plugin. Aujourd’hui, plain de compagnie développe des plugins variés pour Netscape Navigator et Internet Explorer.
Un problème est que les plugins ont l’accès total à des données dans le système, spécialement au système de gestion des fichiers. Si un plugin développés par une mauvaise personne qui a ajouté des mauvaises fonctions dans le plugin, et puis un utilisateur l’installe dans Netscape Navigator, des choses ne pas attendues peuvent se passer. Les implémentations des plugins doivent limiter leurs fichiers de données d’accéder à des autres fichiers. Par exemple, la fonction GetNetText du plugin Macromedia Shockwave peut lire tous les répertoires dans le répertoire de Netscape Navigator.
6.3.2 – ActiveX et Authenticode
ActiveX
ActiveX est une collection de technologies, de protocoles, et d’APIs, développés par Microsoft qui sont employés pour télécharger des codes exécutables sur l’Internet. Les codes sont empaquetés dans un fichier appelé contrôle ActiveX (ActiveX control). Le fichier a l’extension .OCX. Les contrôles ActiveX sont des plugins qui sont automatiquement téléchargés et installés si nécessaires, puis automatiquement supprimé ils ne sont plus utilisé. Les contrôles ActiveX peuvent être écrits même en utilisant le Java. Considérant que les plugins étendent la capacité d’un navigateur de sorte qu’il puisse adapter à un nouveau type de document, la plupart des contrôles ActiveX sont utilisées pour fournir une nouvelle fonctionnalité à une région spécifique d’un page Web.
Il y a deux types contrôle ActiveX, le premier contient les codes de machine qui sont compilés en un fichier exécutable. Le deuxième contient des codes Java, il peut s’exécute dans la machine virtuelle de Java JVM. Pour le deuxième type contrôle ActiveX, la sécurité est la même avec les programmes Java qui s’exécute dans le SandBox. De plus, le navigateur peut permettre les Java contrôles ActiveX des privilèges spécifiques, comme la probabilité d’écriture dans un répertoire, ou ouvrir une connexion à un ordinateur sur l’Internet. Pour le premier type, il n’y a aucune façon de contrôler les fonctions d’un contrôle ActiveX, car ils sont des programmes qui s’exécute directement dans le système d’exploitation.
Authenticode
L’authenticode est une technologie de Microsoft qui permet aux utilisateur d’identifier l’auteur du logiciel et de vérifier que le logiciel n’est pas changé depuis la date ou il est distribué.
L’authenticode utilise la signature digital et le PKI (public key infrastructure).
- Pour les Contrôles ActiveX en code machine: l’authenticode est seulement vérifié une fois qu’il est téléchargé à partir de l’Internet. Si l’ActiveX control est dans le disque dur, il est considéré comme sécurisé.
- Pour les Java Contrôles ActiveX: Avec Internet Explorer, l’authenticode peut être utilisé pour déterminer quelles sont les permissions d’accès que l’ActiveX possède.
Mais l’authenticode n’est pas une solution, une fois qu’un ActiveX control est installé, il n’y a pas de restriction pour lui.
6.4 – Les autres nuisances du Web
Au début du troisième millénaire, la publicité envahit de plus en plus les sites proposés sur le net. On va surtout s’intéresser à la convivialité plutôt qu’à des problèmes purement liés à la sécurité. La publicité sur l’Internet revêt généralement deux formes: les bannières et le fenêtres pop-up.
Les bannières
Les bannières sont des images, le plus souvent animées, généralement situées en haut et en bas des pages Web. Lorsque l’on clique sur ce type d’image, une fenêtre pointant vers le site de la société qui fait de la publicité s’affiche alors à l’écran.
Presque tous les moteurs de recherche ont recours à ce type de publicité. Certains adaptent même les bannières qu’ils insèrent dans leurs pages en fonction des mots clés recherchés par les utilisateurs de ces moteurs.
Rappelons que lorsqu’une bannière est générée par une société de spécialisée autre que celle proposant le site visité, il est techniquement possible de mémoriser la liste des différents sites consultés par un même utilisateur en utilisant des cookies.
Les fenêtres pop-up
Ce type de publicité est le plus souvent particulièrement désagréable, car il consiste en l’affichage d’une petite fenêtre contenant généralement une bannière. Le problème, c’est que si on ferme cette fenêtre, elle sera inlassablement recouverte chaque fois qu’on consultera une nouvelle page du site en question. Et si on laisse ouverte mais ne l’iconifie, elle risque de repasser au premier plan à chaque clic, avec une nouvelle bannière.
7 – Le commerce électronique
On va parler d’un sujet très intéressant, le commerce électronique. Maintenant, on utilise souvent les services de vente en ligne qui nous permettent de rester chez nous en achetant des marchandises sur l’Internet. Un internaute qui veut acheter quelque chose peut entrer dans le site Web de vente, choisir une ou plusieurs marchandises, et puis, de façon quelconque, l’internaute doit faire transférer une somme d’argent à la compte bancaire du marchand. Le marchand va envoyer les marchandises choisis chez l’Internaute. Aujourd’hui, l’utilisation de carte crédit est la façon la plus populaire pour le paiement sur l’Internet.
7.1 – Le paiement avec la carte crédit
Une transaction de carte crédit typique implique cinq parties différentes :
- Le client
- Le marchand: le marchand est le site Web
- La banque du client
- La banque du marchand
- Le réseau bancaire: le réseau qui connecte les banques
Une transaction de carte se compose de dix pas :
1 – Le client donne le numéro de la carte crédit au marchand
2 – Le marchand demande sa banque l’autorisation en lui envoyant un message.
3 – Le réseau bancaire envoie les informations à partir de la banque du marchand à la banque du client
4 – Une réponse est envoyée à la banque du marchand
5 – La banque du marchand informe le marchand que le charge a été approuvée.
6 – Le marchand remplit la commande du client.
7 – Le marchand envoie un ensemble de charge à sa banque
8 – La banque du marchand envoie les requêtes de règlement à la banque du client en utilisant le réseau bancaire.
9 – La banque du client débite la compte du client et placer l’argent dans une compte de règlement inter banque.
10 – La banque du marchand crédite la compte du marchand.
Maintenant il y a des façons différentes utilisées pour transférer le numéro de carte crédit :
- En ligne avec le chiffrement
Le client envoie le numéro de carte sur l’Internet au marchand dans une transaction encryptée. - En ligne, pas de chiffrement
Le client envoie le numéro de carte crédit, doit dans un message électronique, soit dans un requête HTTP de type POST. - En ligne, avec un intermédiaire financier
Pendant le processus de commande, le navigateur du client est momentanément rerouté vers une machine appartenant à un organisme financier (comme Paypal) lors de la saisie des coordonnées bancaire du client. Cet organisme est connecté en direct avec le réseau bancaire, ce qui lui permet d’envoyer une demande d’autorisation en temps réel, le client devant patienter jusqu’à réception d’une réponse.Plus précisément, la plate-forme de paiement de l’organisme financier contacte la banque qui a délivré le numéro de la carte du client, vérifie qu’elle est valide (non volée, compte approvisionné . ..) et renvoie la réponse jusqu’à l’organisme financier.Ce dernier confirme la transaction en signifiant au site de marchand que la commande peut être acceptée, le client n’a plus qu’à attendre le traitement de sa commande.
Dans le dernier cas le marchand n’est jamais en possession du numéro de carte du client et de sa date d’expiration associée. Il n’y a pas de risque de piratage à ce niveau. De plus, le marchand ne peut pas a priori utiliser une fois de plus le numéro de carte, puisqu’il ne le connaît pas. On s’intéresse au premier pas, car dans ce pas le numéro de carte crédit du client est transféré sur l’Internet au site Web de marchand.
7.2 – Risque hypothétique et réel
7.2.1 – Obtention du numéro sur le poste client
L’ordinateur du client est souvent faible. En effet, un virus ou cheval de Troie installé sur le poste du client pourrait facilement intercepter le numéro de sa carte dès sa saisie par l’utilisateur, et l’envoie à un mal individu.
7.2.2 – Interception du numéro durant sa transmission
L’interception d’un numéro de carte bancaire sur l’Internet est le problème le plus fréquemment évoqué lorsqu’on interroge des internautes à s’adonner aux joies du commerce électronique.
Dans le premier cas, l’envoi du numéro de carte en claire (sans chiffrement), on peut possiblement mettre un dispositif d’écoute entre l’ordinateur du client et le site Web du marchand. Cela sera mieux si l’on peut l’installer sur le réseau local du client (le dispositif peut être un programme). Bien sûr que le faire est difficile pour la plupart du monde.
Le second cas, l’envoi du numéro dans une transaction encryptée (le protocole SSL est employé). Cette fois, non seulement il faut installer un dispositif d’écoute sur le trajet du numéro de carte, mais il est nécessaire de décrypter ensuite les informations obtenues afin de récupérer le numéro en clair. Avec la connexion chiffrée en utilisant SSL en 128 bits, il est presque impossible de décrypter les messages.
7.2.3 – Obtention sur le serveur du marchand
Il y a des risques qui se situent du côté du marchand. Supposons que maintenant le marchand soit honnête, il stocke le numéro de carte bancaire sur son serveur. Si un individu a réussit à attaquer le serveur du marchand, il peut avoir des milliers de numéros de carte, y compris vote numéro.
7.2.4 – Découverte d’un numéro via un logiciel spécifique
Il existe des logiciels qui permettent de générer des numéros de cartes bancaires syntaxiquement valides. Avec une probabilité très petite, un individu qui utilise ce logiciel peut obtenir un numéro qui est égal à votre numéro. C’est catastrophe.
7.3 – Les transactions sécurisées
Pour protéger le client des attaquants, la majorité des paiements effectués en ligne sur un site de commerce électronique sont protégés par le protocole SSL (Secure Socket Layer) inventé par Netscape.
7.3.1 – Le protocole SSL
Le SSL a été inventé par l’entreprise Netscape au milieu des années 1990s. La première version de SSL (1.0) voit le jour en juillet 1994. En 1995, la version 3.0 a été née. C’est cette version qui est actuellement utilisée sur la majeure partie des serveurs Web.
Principes de fonctionnement
SSL est un protocole qui intervient entre TCP/TP et les différents protocoles de la couche application tels que SMTP, HTTP. Une de ses principales caractéristiques est de ne pas être lié à un type de protocole particulier mais de pouvoir être utilisé pour insérer une couche de communication sécurisée entre un client et un serveur.
Les trois caractéristiques principales du SSL, en matière de sécurité, sont les suivantes :
- Authentification du serveur:
le client, lorsqu’il se connecte via SSL à un serveur, peut avoir la preuve de l’identité du serveur en question grâce à l’utilisation de certificats numériques. - Authentification du client:
cette fois, c’est le serveur qui peut s’assurer de l’identité de la personne connectée. Cette fonctionnalité n’est généralement pas utilisée dans le cadre du commerce électronique mais plutôt lorsqu’il s’agit de sécuriser l’accès à des informations sensibles. - Chiffrement de la session:
l’objectif est d’empêcher que des informations transmises entre le client et le serveur ne puissent être interceptées ou même modifiées par des tiers. Des mécanismes de chiffrement sont utilisés dans ce but.
Plus précisément, SSL utilise successivement des algorithmes à clé publique pour authentifier le serveur (voire le client) et à clé secrète pour chiffrer les transactions. En fait SSL se compose de deux parties: SSL Record et SSL Handshake. Le premier décrit le format des données, qui seront transmises au cours d’une session protégée par SSL. Le second, il intervient lorsqu’un client et un serveur veulent ouvrir une session de SSL entre eux. Il consiste en l’échange d’un certain nombre de messages, codés grâce au protocole SSL Record, et associés à des traitement effectués simultanément sur le client et le serveur. Si ces échanges réussissent, la session SSL est active et utilisable par l’application qui l’a initié.
Suites cryptographiques
Les algorithmes cryptographiques utilisés dans SSL sont classés selon différentes catégories, appelés cipher suite, ou suite cryptographiques, associant un algorithme de chiffrement, avec une clé de longueur déterminé, à un algorithme de condensation (compression) pour assurer les fonctions d’authentification.
Les algorithmes d’échange de clés sont également employés afin de générer une clé de session qui servira à chiffrer les transactions. On utilise le plus souvent le RSA. Voici les différents suites cryptographiques utilisant RSA. Les deux premières sont autorisés seulement au Etats Unis
- Suite cryptographique la plus forte:
chiffrement Triple DES avec une clé de 168 bits et une authentification de messages via SHA. - Suites cryptographiques fortes:
chiffrement RC4 avec une clé de 128 bits et une authentification basée sur MD5 et DES à 56 bits avec SHA. - Suites cryptographiques exportables:
Chiffrement RC4 avec une clé de 40 bits et une authentification MD5 et RC2 avec une clé de 40 bits et MD5. Ces suites sont incorporées aux versions exportables des navigateurs. - Suite cryptographique la plus faible:
Pas de chiffrement, authentification MD5. Cette suite n’assure que l’authentification et la détection de modification, pas la confidentialité des informations transmises.
Chaque client compatible SSL, de même chaque serveur, dispose d’une liste de suites cryptographiques susceptibles d’être employés. C’est durant la phase de négociation, exécuté grâce au protocole SSL Handshake, qu’est sélectionnée la suite la plus porte, reconnue simultanément par le client et par le serveur.
Ex: dans Mozilla, dans l’item menu Edit – Preferences – Privacy et Security – SSL – Edit Ciphers on peut voir les suites cryptographiques reconnues par Mozilla.
Le protocole SSL Handshake
Toute session SSL est initiée grâce au protocole SSL handshake. Au début, le client qui souhaite établir une connexion envoie un message « ClientHello » au serveur, et le serveur doit y répondre un message ServerHello. Si le client ne reçoit pas de message de « ServerHello », la connexion ne peut pas être établie. Les messages « ClientHello » et « ServerHello » sont utilisés pour établir les attribues de la session: la version du protocole SSL, l’ID de la session, la suite cryptographique va être utilisé, et la méthode de compression. De plus, deux numéros aléatoires sont générés et échangés.
ClientHello.random et ServerHello.random.
Après le message « ServerHello », le serveur envoie son certificat (certificat de serveur). Si le serveur est déjà authentifié, il peut demander un certificat du client avec le message « CertificateRequest », si c’est approprié à la suite cryptographique choisie. Si le serveur a envoyé le message « CertificateRequest », le client doit envoyer le message de certificat « certificate message » ou un message « no certificate ». Maintenant le message « client key exchange » est envoyé, et le contenu du message dépend de l’algorithme de clé publique choisi.
En ce moment, un message « change cipher spec » est envoyé par le client. Le client envoie immédiatement le message « finished ». Le serveur va envoyer son message « change cipher spec », et envoyer son message « finished ». Au moment là, la négociation est complète et le client et le serveur peuvent échanger des données.
Si le serveur demande le certificat du client, tandis que le client n’en a pas, le client envoie le message « no certificate ». Cette erreur n’est pas grave dans le cas que le serveur n’envoie pas le message « fatal handshake failure ». Au contraire, la connexion échoue.
On présente un exemple dans le cas où seul le serveur est authentifié:
- Le client envoie le message « ClientHello » contenant la version de SSL qu’il supporte, la listes des suites cryptographiques qu’il reconnaît, une valeur aléatoire, l’identifiant de session.
- Le serveur envoie un message « ServerHello » ayant une structure identique à celui du client. Il envoie aussi son certificat.
- Le client vérifie l’authenticité du certificat serveur. Si cette opération se déroule correctement, le serveur est authentifié et on peut passer à l’étape suivante. Si non, la session échoue.
- Le client établit un pré-secret maître pour la session, avec la collaboration éventuelle du serveur, selon l’algorithme utilisé. Il chiffre ce pré-secret à l’aide de la clé publique du serveur qu’il a obtenue, et l’envoie au serveur.
- Le serveur utilise sa clé privée afin de déchiffrer le pré-secret. Le client et le serveur génèrent alors, chacun de son côté, un secret maître, à partir du pré-secret. Les deux secrets du serveur et du client sont égaux.
- Le client et le serveur génèrent les clés de session à partir du secret maître qu’ils partagent, permettant de chiffrer les informations transmises et de vérifier leur intégrité.
- Le client envoie un message informant le serveur de la suite cryptographique qu’il utilise ainsi qu’un message marquant la fin du protocole, chiffré à l’aide de la clé de session générée à l’étape précédant.
- Le serveur envoie le même type de message au client.
- Le protocole SSL Handshake est terminé: le client et le serveur peuvent communiquer de façon sécurisée.
Authentification du serveur
Comme on a dit au session précédente, un certificat serveur contient les champs suivants :
- La longueur de la signature (du AC)
- le numéro de certificat
- l’algorithme de la signature
- le nom distingué
- le nom du sujet. C’est le nom DNS du serveur.
La vérification du certificat du serveur comporte plusieurs phases :
- Le client examine la date de validité du certificat et vérifie qu’elle n’a pas été dépassée.
- Si le client reconnaît le AC ayant délivré le certificat, on passe à la phase suivante.
- Le client vérifie la signature du certificat serveur à l’aide de la clé publique de AC qui l’a délivré. Si cette signature est valide, on peut considérer que le certificat est valide aussi, et voilà le serveur est authentifié. Il reste une phase.
- Le client examine l’adresse de la machine à laquelle le certificat a été délivré et vérifie qu’elle correspond à celle du serveur auquel le client est connecté. Cette vérification est importante, car elle permet d’éviter qu’un tiers malveillant qui vienne s’insérer entre le serveur et le client.
7.3.2 – Reconnaître une transaction sécurisé
Selon le logiciel de navigation utilisé, différents symboles ou éléments permettent se savoir qu’une session sécurisé par SSL est ouverte. Il y a deux petits qui indiquent que l’utilisateur est en train être dans une session sécurisée. Le premier se situe au bar d’adresse des navigateurs, l’URL ne commence pas par http:// mais par https://. Le second point est l’icône en forme de cadenas qui apparaît en bas à droite ou à gauche de la fenêtre des navigateurs.
Dans Internet Explorer:
![]()
Dans Netscape Navigator ou Mozilla:
![]()
Ces deux détails prouvent que la session est sécurisée, mais on ne sait rien des caractéristique de la session (suite cryptographique utilisée) ou du contenue du certificat du serveur. Ces informations peuvent être obtenues en utilisant des menu items fournies par des navigateurs.
7.3.3 – Quelques conseils pratiques pour les utilisateurs
- Choisir les sites importants
- Les sites marchand appartenant à des enseignes célèbres de la grande distribution présentent peu de risque pour les internautes.
- Renseigner-vous sur le société
On peut facilement trouver des renseignements sur les sites de commerce électronique, en lisant la presse par exemple ou les classements ou listes de sites proposés par certains serveurs comme Yahoo. - Tenter d’entrer en contact avec le service clien
Essayez d’entrer en contact avec le service clients par courrier électronique ou téléphone. On peut vous donner des informations utiles sur la livraison de la marchandise que vous avez acheté. - Lire les conditions générales de vente
Tout site sérieux doit mettre à disposition de ses clients ses conditions générales de vente. Si un tel document n’est pas accessible, ce n’est pas très bon signe. Il faut le lire attentivement avant de décider d’acheter quelque chose. - Eviter les sites qui n’utilise pas SSL
Cela est bien sûr. - Choisir le mot de passe long et complexe
Quand un site se propose de conserver des coordonnées, en particulier bancaires, il est conseillé de choisir un mot de passe relativement long (au moins 8 caractères) et complexe (mélange chiffre, lettres minuscule et majuscule …). Cela est toujours bon pour tout mot de passe. - Préférer un marchand passant par un intermédiaire financier
Chaque fois qu’on achète un bien à l’un des sites utilisant l’intermédiaire financier, on n’a plus besoin d’indiquer le numéro de carte crédit.
7.4 – Autre dispositifs de paiement
7.4.1 – Le porte-monnaie électronique
Une des limitations principales de la carte bancaire est qu’elle ne permet pas d’effectuer des micro paiements, cad des paiements d’un montant égal à quelques Euros. Techniquement, rien n’empêche d’acheter une marchandise valant quelques Euros, cependant le pourcentage que la banque va charger sur votre transaction sera impactant. Alors il devient difficile de vendre des marchandises à prix bon marché.
C’est pourquoi le porte-monnaie électronique (PME) est né. Il s’agit de créditer un compte, ex avec une carte bancaire, d’un montant d’une dizaine d’Euros, permettant ainsi d’effectuer des petit achats. Un exemple de PME est le service K-Wallet de Kleline. Il s’agit de créer gratuitement un porte monnaie virtuel (PMV), sur les serveur de Kleline, en indiquant vos coordonnées postales et bancaires. Une fois que le PMV ouvert, il suffit de se rendre sur un des sites marchands qui ont adopté le système et de choisir le paiement avec K-Wallet. Votre identifiant et votre mot de passe sont demandés afin d’effectuer le paiement.
Dans ce cas le marchand n’a jamais connaissance du numéro de carte du client, et ce numéro n’est transmis qu’une seule fois à Kleline, lors de l’enregistrement. De plus, on ne doit pas installer aucun logiciel sur l’ordinateur du client.
7.4.2 – SET
Le SET (Secure Electronic Transaction) est un protocole pour envoyer l’information de carte de paiement sur l’Internet. SET a été conçu pour encrypter certain message de type spécifique qui concerne le paiement. Les principaux objectifs de SET sont d’assurer l’intégrité et la confidentialité des transactions sur l’Internet, comme SSL, mais avec authentification obligatoire de chacun des intervenants à l’aide des certificats.
Dans une transaction typique de SET, il y a des informations privées entre le client et le marchand, et aussi des informations privées entre le client et la banque. Le SET permet les deux types d’information privée peuvent être embarqués dans une seule transaction signée en utilisant une structure cryptographique appelée « signature double » (dual signature).
Un message de requête se compose de deux champs: un pour le marchand, et un pour la banque du marchand. Le champ de marchand est crypté avec la clé publique du marchand, et l’autre est crypté avec la clé publique de la banque du marchand. En plus, le message de demande contient des digests de chacun des deux champs, et une signature. La signature est obtenue en unifiant ces deux digests, et en signant le digest obtenu.
La norme SET ne fournit pas directement au marchand le nombre de carte crédit du client, mais la banque de marchand peut, à son option, fournir le nombre au marchand quand elle (la banque) envoie la confirmation au marchand.
8 – Logiciel de blocage et technologie de censure
Les chercheurs ont recherché des manières de contrôler des informations que les sites Web contiennent. Pourquoi ils doivent les contrôler?
- Certains croient que l’information sur l’Internet au sujet du sexe et de la sexualité, des drogues, et des thèmes semblables inadéquate pour les jeunes.
- Quelques politiciens croient que des écritures des crimes devraient être interdites.
- Quelques politiciens croient que les informations sur des élections libres et des systèmes politiques démocratiques peuvent déstabiliser à leurs régimes.
La censure est la suppression officielle des idées, des journaux, des films, des lettres, ou d’autres publications. Des logiciels de blocage et des technologies de censure sont nés, basé sur les idées ci-dessus.
8.1 – Logiciel de blocage
La tendance la plus récente maintenant est que les entreprises développent des logiciels de censure/blocage pour des ordinateurs à la maison. Ces logiciels de blocage emploient des techniques suivantes pour accomplir leurs objectifs :
- la liste des sites d’exclusion
- le blocage basé sur les mots clé de nom des sites et des pages
- le blocage basé sur les mots clé dans le contenu
- le blocage basé sur des données transmises
Des logiciels de blocage peuvent fonctionner au niveau de couche d’application, bien intégrité avec des navigateurs ou des logiciels de messagerie. De plus, ils peuvent fonctionner au niveau de protocole, contrôler les connexions sur le Net. Finalement, ils peuvent fonctionner au niveau de couche de réseau.
8.1.1 – Problème des logiciels de blocage
Le plus grand problème technique est la difficulté de maintenir la base de donnée et la distribution de cette base de donnée. Par exemple, la liste des sites d’exclusion peut changer rapidement. Quelques sites essayent de cacher la nature vraie de leurs sites en choisissant un nom de DNS et des pages inoffensifs.
8.2 – PICS
Le PICS (Platform for Internet Content Selection) est un effort à développer un plate-forme sur l’Internet pour échanger les informations concernant le contenu des sites Web et créer des logiciels de blocage automatiques.
8.2.1 – Que c’est PICS
PICS est une norme pour étiqueter le contenu des documents qui apparaissent sur le World Wide Web. Les étiquettes de PICS contiennent un ou plusieurs classement qui sont publiés par un service de classement. (Un service de classement est un individu, un groupe, une organisation ou une entreprises qui fournit les étiquettes PICS pour des informations sur le Web. Les étiquettes qu’un service de classement fournie sont basés sur un système de classement).
Un système de classement spécifie les dimensions utilisées pour étiqueter, les valeurs permises dans chaque dimension, et une description du critère utilisée dans la valeur assignée. Par exemple, le système de classement MPAA classe des films aux Etats Unis basé sur une seule dimension dont les valeurs permises sont G, PG, PG-13, R et NC-17.
Par exemple, une étiquette de PICS peut dire que une page Web particulière contient des images pornographiques. Une étiquette PICS peut dire que une collection des pages dans un site Web contiennent des contenus concernant la violence. Une étiquette PICS peut dire que toute page dans un site Web sont historiquement imprécis.
Une étiquette peut être associée avec un ensemble de fichier dans un site, un site entier, ou une collection de site. De plus, une étiquette PICS peut être associée avec un document particulier, ou même une version particulière d’un document. Les étiquettes PICS peuvent être signées pour assurer la confidentialité.
Les étiquette de PICS peuvent être ignorées, donc l’utilisateur a l’accès total aux sites Web. Elles peuvent être interprétées par le navigateur ou par le système d’exploitation. Une organisation entière ou même un pays peut avoir une politique de PICS en utilisant un serveur proxy de blocage dans un firewall.
Les applications qui implémente la norme PICS ont plus d’avantages que celles de blocage simple :
- Le PICS permet de bloquer chaque document.
- Le PICS permet d’obtenir les ratings de plusieurs sources.
- Des différents utilisateurs peuvent avoir les différents règles d’accéder.
8.2.2 – Application de PICS
Le PICS peut être utilisé pour assigner plusieurs type d’étiquette différents à plusieurs types différents d’information :
- L’étiquette PICS peut spécifier le type ou la quantité de sexe, nudité dans un document
- L’étiquette PICS peut spécifier la précis historique d’un document.
- L’étiquette PICS peut spécifier la point de vue politique d’un document ou de son auteur.
- L’étiquette PICS peut spécifier si un photo est trop noir ou trop blanche
- L’étiquette PICS peut spécifier l’an quand le document a été créé. Il peut dénoter l’état le droit d’auteur ou n’import quel droit spécifié par l’auteur du document.
- L’étiquette PICS peut indiquer si une salle de babillage soit modérée ou non.
- L’étiquette PICS peut être appliqué aux programmes. Par exemple, une étiquette peut indiquer si un programme a été testé et approuvé par un laboratoire.
Clairement, le PICS est spécifiquement conçu pour donner une opinion de personne particulière ou d’autorité marquante d’un document.
8.2.3 – Implémentation de PICS
Une étiquette se compose de trois éléments: l’identifiant de service de classement (un URL), les options de l’étiquette, et le classement. Les options ajoutent les propriétés supplémentaires du document classé et du classement lui-même. Le classement est un ensemble des paires attribut-valeur qui décrit le document dans une ou plusieurs dimensions. Une ou plusieurs étiquettes peuvent être distribuées dans une listes.
(PICS-1.1 <l'url de service> [option...] labels [option...] ratings (<category> <value> ...) [option...] ratings (<category> <value> ...) ... <service url> [option...] labels [option...] ratings (<category> <valeur> ...) [option...] ratings (<category> <valeur> ...) ... ...)
Exemple :
(PICS-1.1 "http://www.gcf.org/v2.5" by "John Doe" labels on "1994.11.05T08:15-0500" until "1995.12.31T23:59-0000" for "http://w3.org/PICS/Overview.html" ratings (suds 0.5 density 0 color/hue 1) for "http://w3.org/PICS/Underview.html" by "Jane Doe" ratings (subject 2 density 1 color/hue 1))
Dans cette étiquette, le service de classement est http://www.gcf.org/v2.5. Cette étiquette est valide de 05/11/1994 à 31/12/1995, appliquée sur deux documents http://w3.org/PICS/Overview.html et http://w3.org/PICS/Underview.html. L’étiquette montre que le premier document a le niveau de densité de 0, de couleur/hue de 1…. L’étiquette est créée par Jane Doe.
Une étiquette de PICS peut être transmise en utilisant trois méthodes :
Dans un document HTML
En utilisant une balise META, on peut embarquer une ou plusieurs étiquettes dans l’entête d’un document HTML.
<META http-equiv="PICS-Label" content='labellist'>
Exemple :
<HTML><HEAD><TITLE>Joes Bookstore</TITLE> <META http-equiv="PICS-Label" content='( PICS-1.1 "http://www.service1.org/v1.0" labels on "1996.10.05T05:15-0500" for "http://www.my.org/etc/mypage.html" ratings (s 0 v 0 g 0) "http://www.service2.org/v1.2" labels on "1996.10.05T08:15-0700" for "http://www.my.org/etc/mypage.html" ratings (com 2 edu 1) )'> </HEAD>
Dans cet exemple on peut voir dans l’entête du requête deux étiquettes ensembles, classée par deux services de classement.
Dans un document transmis via le protocole qui utilise l’entête RFC 822
Les étiquettes peuvent être transmises en utilisant n’importe quel protocole qui utilise l’entête du standard RFC 822 comme SMTP. En plus, il y a une extension pour le protocole HTTP qui permet un client HTTP (le navigateur) de faire une requête demandant quelles étiquettes qui vont être transmises avec le document.
Ex: le client envoie au serveur HTTP une requête demandant les étiquettes du document /foo.html
GET /foo.html HTTP/1.0
Protocol-Request: {PICS-1.1 {params full {services "http://www.gcf.org/v2.5"}}}
Le serveur répond :
HTTP/1.0 200 OK
Date: Thu, 30 Jun 1995 17:51:47 GMT
Last-modified: Thursday, 29-Jun-95 17:51:47 GMT
Protocol: {PICS-1.1 {headers PICS-Label}}
PICS-Label:
(PICS-1.1 "http://www.gcf.org/v2.5" labels
on "1994.11.05T08:15-0500"
exp "1995.12.31T23:59-0000"
for "http://www.greatdocs.com/foo.html"
by "George Sanderson, Jr."
ratings (suds 0.5 density 0 color/hue 1))
Content-type: text/html
...contenu de foo.html...
Dans cet exemple, le client demande le serveur Web courant (www.greatdocs.com) les étiquette concernant le document /foo.html, et fournies par le service de classement est www.gcf.org/v2.5.
Séparément du document :
Un client peut demander des étiquettes à partir d’un serveur qui supporte le protocole HTTP. Pour demander des étiquettes, un client contacte un bureau d’étiquette. Un bureau d’étiquette est un serveur HTTP qui comprend les requêtes en syntaxe particulier. Ce bureau fournie des étiquettes pour les documents dans des serveurs différents, même pour les documents qui sont disponibles sur des autres protocoles.
Exemple :
GET /Ratings?opt=generic& u="http%3A%2F%2Fwww.questionable.org%2Fimages"& s="http%3A%2F%2Fwww.gcf.org%2Fv2.5" HTTP/1.0
Le serveur renvoie un document de type « application/pics-labels » qui contient l’étiquette demandée.
8.2.4 – PICS et la censure
Sans PICS, les parents qui veulent protéger leurs enfants des mauvaises informations peuvent effectuer des solutions autoritaires :
- Interdire de surfer sur l’Internet
- Interdire d’accéder au site qui apparaît avoir des mauvaises informations
- Surveiller les enfants tout temps quand ils accèdent l’Internet
- Rechercher les solutions légales
Le PICS donne aux parents des autres options. Les navigateurs peut être configurés tel que les documents qui ont des classements inconvenables ne sont pas affichés. Des navigateurs intelligents pourraient même « prefetch » les classements pour tous liens d’hypertexte, les liens à des documents inconvenables ne seraient pas affichés.
Puisque des différentes personne peuvent avoir des différentes idées, le PICS est conçu pour supporter plusieurs service de classement. Le PICS est un standard ouvert, n’importe quelle dimension qui peut être quantifiée peut être classée. Et puisqu’une organisation ne peut jamais classer toute information sur le Web, le PICS permet au éditeurs Web de classer leur contenu. Les parents ont l’option de décision de l’acceptation les classements assignés leur même ou non.
Les logiciels de blocage fonctionnent au niveau du protocole TPC/IP pour bloquer l’accès à un site entier. Au contraire, le PICS peut contrôler l’accès à chaque document. C’est le grand avantage de PICS, qui fait que le système devient bien adapter à des librairies électroniques. Les enfants peuvent accéder au livre Harry Potter, mais pas d’accès aux sites illicites.
8.3 – RSACi
RSAC est le nom de l’organisation Recreational Software Advisory Council. Elle est formée dans des années 1990s aux Etats Unis pour régler les jeux vidéo des enfants. L’organisation W3C a développé une version modifiée de RSAC appelé RSACi utilisé pour classer les sites Web. Le but de RSACi est de protéger les enfants des informations inconvenables sur le Web.
L’utilisateur peut configurer le navigateur pour permettre d’accéder aux sites Web basés sur des objectifs déclarés dans l’étiquette ou non. Les catégories de filtrage sont :
- Babillage
- La langue utilisé sur le site
- La nudité et le contenu sexuel d’un site
- La violence sur le site
- Les autres tels que jeu, les drogues et l’alcool
Les navigateurs célèbres maintenant comme Internet Explorer et Netscape Navigator, supportent RSACi.
9 – P3P – Privacy Preferences Project
9.1 – P3P, qu’est-ce que c’est ?
P3P – Platform for Privacy Preferences est un protocole qui permet des sites Web d’exprimer l’utilisation des informations personnelles des internautes dans un format standardisé qui peut être obtenu automatiquement et interprété facilement par des agents d’utilisateur. Les agents P3P informent les internautes de l’utilisation des informations personnelles (dans deux formats: l’un est lisible par des agents, et l’autre est lisible par l’utilisateur), et prendraient la décision basé sur ces informations quand approprié. Les internautes ne doivent pas lire la politique d’intimité dans tous les sites qu’ils visitent.
Tandis que P3P fournie un mécanisme technique pour assurer que les internautes peuvent être informés à propos de la politique d’intimité avant ils entrent les informations personnelles dans des formes, P3P ne fournie pas de mécanisme technique pour assurer que les sites Web respectent leurs politiques. De plus, P3P ne fournie pas des mécanismes pour sécuriser des informations personnelles sur la ligne de communication.
9.2 – Vocabulaire de P3P
Cinq premiers topiques est pour but de faire comprendre l’utilisateur sur ce que le site Web va faire.
- Qui est entrain de collecter cette donnée.
- Quelle information est entrain d’être collectée.
- Pour quelle but.
- Quelles informations vont être partagés avec d’autre (site)
- Qui va recevoir ces informations
Et les quatre topiques ci-dessous expliquent la politique d’intimité interne du site Web :
- Peuvent les utilisateurs changer l’utilisation de ces données.
- Comment les disputes peuvent être résolues.
- Quelle est la politique pour retenir des données.
- Où on peut trouver la politique détaillée dans la forme lisible par l’humain.
9.3 – Comment ça marche
Le P3P permet les sites Web de traduire politique de pratique dans un format standardisé, lisible par la machine (XML) qui peut être obtenu automatiquement et interprété facilement par des agents d’utilisateur. La traduction peut être effectués manuellement ou avec des outils automatiques. Une fois complété, le site Web peut informer les utilisateurs automatiquement qu’il supporte le P3P.
A côté du client, le client P3P lire la politique d’intimité automatiquement dans le site Web. Un navigateur équipé par P3P peut vérifier la politique d’intimité d’un site Web et informer l’utilisateur de l’utilisation des informations personnelles du site Web. Le navigateur peur alors le comparer automatiquement avec les critères d’intimité de l’utilisateur. Un client P3P peut être embarqué dans des navigateurs, des plugins, ou les autres logiciels.
9.4 – P3P version 1.0
La spécification P3P 1.0 définit la syntaxe et la sémantique de P3P, et la mécanisme pour associer les politiques avec les ressources Web. Les politiques P3P sont constitués en utilisant le vocabulaire P3P pour expliquer la pratique d’intimité. Les politiques P3P référencement aussi des éléments de la schéma des données élémentaires P3P, un ensemble standardisé des données élémentaires que tous les agents de P3P doivent en avoir la conscience.
9.4.1 – Buts et capacités de P3P 1.0
Le P3P 1.0 fournie une façon pour des sites Web peuvent coder l’utilisation dans un format XML lisible par la machine. Ce format s’appelle la politique P3P. La spécification P3P 1.0 définit :
- Une schéma standardisé pour des données qu’un site Web veut collecter (P3P base data schéma)
- Un ensemble standardisé des utilisateurs, des destinataires, des catégories de donnée.
- Un format XML pour représenter la politique d’intimité.
- Une façon pour associer les politiques d’intimité avec des pages Web, ou des sites, des cookies.
- Un mécanisme pour transporter les politique P3P en utilisant le protocole HTTP.
9.4.2 – La politique P3P
La politique P3P utilise un XML avec le namespace qui code le vocabulaire P3P pour la présentation de la pratique privé dans une politique P3P, énumérer des types de donnée ou des éléments de donnée collectés, et expliquer comment les données vont être utilisées. Les politiques doivent couvrir toutes les données concernées (à collecter). Chaque politique P3P est appliquée à une partie particulière des ressources d’un site Web qui sont listés dans un fichier de référence.
9.4.3 – Agent d’utilisateur P3P
Des agents d’utilisateur P3P peuvent être embarqués dans des navigateurs, des plugins du navigateur, ou dans des serveurs proxy. Ils peuvent être implémenté comme les applets de Java ou Javascript, ou embarqués dans les logiciels qui entrent automatiquement des données sur les formes, ou dans des outils de gestion des informations personnelles. Ces agents peuvent prélever la politique à partir d’une location indiquée, l’interpréter, et afficher les symboles, jouer un son, ou générer un message qui reflètent la pratique de l’intimité du site. Ils peuvent aussi comparer les politiques P3P avec la préférence d’intimité mise par l’utilisateur et effectuer des actions appropriées.
9.4.4 – Implémentation de P3P 1.0 sur le serveur
Le P3P peut être implémenté dans un serveur Web qui est compatible avec le protocole HTTP 1.1. Les serveurs peuvent publier ses fichiers de référence à un lieu bien connu, ou ils peuvent placer ces fichiers dans le contenu du fichier HTML/XHTML en utilisant la balise link. Un serveur peut être configuré pour insérer une extension P3P à toute réponse HTTP qui indique la location d’un fichier de référence du site.
9.4.5 – Un exemple
Je veux donner un exemple sur l’utilisation de P3P. Par exemple, A veut acheter une marchandise au site IBM. Supposons que IBM place des politiques sur toute page dans son site, et A utilise un navigateur qui supporte P3P.
A type l’adresse www.ibm.com dans le bar d’adresse du navigateur. Le navigateur télécharge la politique P3P de cette page. La politique dit que les donnée que le site collecte ne sont que des données trouvées dans la requête HTTP. Alors le navigateur vérifie si cette politique est acceptable, en la comparant avec la préférence d’intimité de A. Supposons que A a permit le navigateur que cela est acceptable. Dans ce cas, la page est affichée normalement, et il n’y a pas de fenêtre pop-up. Ensuite, A clique sur le catalogue de IBM.
Supposons que dans cette page, IBM utilise des cookies pour implémenter une charrette commerciale (« shopping cart »), et A permet les sites Web d’utiliser des cookies. Lorsqu’il y a plus d’information qui est entrain d’être collectée dans cette session du site, le serveur fournie une autre politique P3P pour couvrir cette session. Une fois de plus, supposons que cette politique est acceptable pour le navigateur de A. A continue et sélectionne quelques marchandises préférées. Enfin A entre dans la page de paiement.
La page de paiement de IBM demande quelques informations supplémentaires: le nom, l’adresse, le numéro de carte crédit, et le numéro de téléphone. Une autre politique P3P est disponible, elle décrit que les informations demandées vont être utilisées seulement pour compléter cette transaction. Le navigateur examine cette politique. Imaginons que A a dit au navigateur que le navigateur doit afficher un message dans le cas d’un site lui demande d’entrer le numéro de téléphone. Dans ce cas, le navigateur va afficher un message pop-up qui dit que le site Web demande A d’entrer le numéro de téléphone, et le message explique le contenu de la déclaration P3P. A peut décider s’il est acceptable pour lui. Si il l’accepte, el peut compléter la transaction, ou il peut annuler la transaction si non.
9.4.6 – La location du fichier de référence
Ce sont des mécanismes utilisés pour indiquer la location du fichier de référence des politiques.
- Dans une location bien connue
- Un document peut indiquer la location en utilisant la balise link du HTML
- Un document peut indiquer la location en utilisant la balise link du XHTML
- Dans l’entête du réponse HTTP.
Les politiques sont appliquée au niveau de ressource. Une page peut se composer de plusieurs ressources, et chacun peut avoir une politique associée à lui.
Une location bien connue
Les sites Web qui utilisent P3P peuvent placer le fichier de référence de politique à une location bien connue. Pour le faire, le fichier de référence de politique doit se situe dans le site à /w3c/p3p.xml. En utilisant ce mécanisme, les sites peuvent assurer que leurs politiques P3P sera accessible pour des agents P3P avant n’importe quelles autres ressources. Si un site choisit ce mécanisme, le fichier de référence dans la location bien connue ne doit pas couvrir le site entier. Par exemple, un site dont le contenu n’est pas à une seule organisation peut ne pas choisir ce mécanisme, ou peut choisir à utiliser un fichier de référence qui couvre une partie du site. Ce mécanisme n’exclure pas l’utilisation des autres mécanismes.
Dans l’entête HTTP
Un document téléchargé par le protocole HTTP pointe à un fichier de référence en utilisant un nouveau champ dans l’entête: P3P. Si un site utilise des entêtes P3P, il doit inclure ces champs dans toute réponses pour toute requête. La syntaxe de l’entête P3P est comme suit:
p3p-header = `P3P: ` p3p-header-field *(`,` p3p-header-field)
dont:
p3p-header-field = policy-ref-field | compact-policy-field | extension-field
dont:
policy-ref-field = `policyref= »` URI-reference ` »`
dont:
extension-field = token [`=` (token | quoted-string) ]
Une entête P3P se compose d’un mot P3P au début, et des champs d’entête P3P. Chaque champ d’en tête P3P se compose de trois options: le champ de référence de politique, le champ de politique compacte, et un champ d’extension. Le champ de référence de politique donne un URI qui spécifie la location du fichier de référence de politique. Quand le URI est relative, cet URI va être interprété relativement avec le URI demandé. Cet URI ne doit pas être utilisé pour l’autre but sauf la but d’indication de la location le fichier de référence de politique.
L’URI est l’abréviation de « Uniform Ressource Indicator ». On a aussi les termes l’URL (Uniform Ressource Locator) et l’URN (Uniform Ressource Name). Un URI peut être classé (considéré) comme un URL ou un URN, ou tous les deux. La terme URL spécifie un sous ensemble de URI, cet ensemble identifie les ressources via la représentation de son premier mécanisme d’accès (la location
du réseau). On peut identifier la ressource par nom (URN) ou par des autres attribues de cette ressource. Le terme URN spécifie un sous ensemble de URI dont un URN doit être globalement unique et persistant, même dans le cas que la ressource devienne indisponible.
Le champ de politique compacte est utilisé pour spécifier les politiques compacte. Il est facultatif. Le champ d’extension n’est pas obligatoire. Il va être utilisé dans les nouvelle version de P3P. Il est aussi facultatif.
Par exemple, le client fait une requête :
GET / HTTP/1.1? Host: www.yahoo.com? User-Agent: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.4) Gecko/20030624? Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/ plain;q=0.8,video/xmng, image/png,image/jpeg,image/gif;q=0.2,*/*;q=0.1? Accept-Language: en-us,en;q=0.5? Accept-Encoding: gzip,deflate? Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7? Keep-Alive: 300? Connection: keep-alive?
Le serveur répond :
HTTP/1.1 200 OK Date: Sat, 19 Jul 2003 08:12:43 GMT P3P: policyref="http://p3p.yahoo.com/w3c/p3p.xml" Cache-Control: private Connection: close Content-Type: text/html
Utiliser la balise link dans un document HTML
Le serveur peut utilise une balise link qui indique la location du fichier de référence de politique P3P. Avec cette méthode, on de doit pas changer le comportement du serveur.
P3p-link-tag = <link rel= »P3Pv1″ href= »URI »>
Par exemple :
<link rel="P3Pv1" href="http://catalog.example.com/P3P/PolicyReferences.xml">
Utilise la balise link dans un document HTML
P3P supporte XHTML aussi. Le serveur peut utiliser un module link XHTML qui indique la location du fichier de référence de politique.
Par exemple :
<link rel="P3Pv1" href="http://tuanno.com/P3P/politique.xml"/>
Les politiques compactes
Les politiques compactes sont des politiques P3P récapitulés qui fournies des conseils à des agents pour que ces agents puissent prendre des décisions vite. Les politiques compactes sont une optimisation de performance dont sa présente n’est pas obligatoire pour les agents comme les serveurs. Un agent d’utilisateur qui ne peut pas obtenir assez d’information à prendre une décision doit obtenir la politique normale.
Dans P3P 1.0, les politiques compactes contiennent des information politiques concernant seulement les cookies. Le serveur Web doit construire les politiques compactes pour représenter des politiques sur les cookies dans la politique entière.
Syntaxe de la politique compacte
compact-policy-field = `CP="` compact-policy `"`
compact-policy = compact-token *(" " compact-token)
compact-token = compact-access |
compact-disputes |
compact-remedies |
compact-non-identifiable |
compact-purpose |
compact-recipient |
compact-retention |
compact-categories |
compact-test
Commencer par le mot CP, la politique compacte se compose de plusieurs marques dont les valeurs possibles sont listés ici. Chaque type de la marque compacte peut avoir des valeurs différentes, par exemple, la marques d’accès (compacte access) peut prendre les valeurs NOI, ALL, CAO, IDC, OTI, et NON. La valeur CAO signifie que le site Web peut collecter les informations de contact de l’utilisateur et les autres informations identifiant l’utilisateur.
Par exemple, ici c’est la politique compacte du site www.msn.com:
P3P:CP= »BUS CUR CONo FIN IVDo ONL OUR PHY SAMo TELo »
Quand une politique compacte trouvée dans une entête HTTP, elle est appliquée aux cookies implémentés dans la réponse courante.
9.4.7 – Le fichier de référence de politique et le fichier de politique
On ne va pas plus loin sur les détails du format de ce fichier. Mais je veux donner un exemple simple. Supposons qu’un site Web veut faire des choses suivantes :
- La politique /P3P/Policies.xml#first est appliquée au site entier, sauf les ressources qui commencent par /catalog, /cgi-bin or /servlet.
- La politique /P3P/Policies.xml#second est appliquée aux ressources qui commencent par /
- La politique /P3P/Policies.xml#third est appliquée aux ressources qui commencent par / cgi-bin ou /servlet, sauf /servlet/unknown
- ll y a pas de politique qui est appliquée aux ressources qui commencent par / servlet/unknown
- Ces politique est valide pendant deux jours.
Ces instructions peuvent être représentées dans ce fichier .XML :
<META xmlns="http://www.w3.org/2002/01/P3Pv1"> <POLICY-REFERENCES> <EXPIRY max-age="172800"/> <POLICY-REF about="/P3P/Policies.xml#first"> <INCLUDE>/*</INCLUDE> <EXCLUDE>/catalog/*</EXCLUDE> <EXCLUDE>/cgi-bin/*</EXCLUDE> <EXCLUDE>/servlet/*</EXCLUDE> </POLICY-REF> <POLICY-REF about="/P3P/Policies.xml#second"> <INCLUDE>/catalog/*</INCLUDE> </POLICY-REF> <POLICY-REF about="/P3P/Policies.xml#third"> <INCLUDE>/cgi-bin/*</INCLUDE> <INCLUDE>/servlet/*</INCLUDE> <EXCLUDE>/servlet/unknown</EXCLUDE> </POLICY-REF> </POLICY-REFERENCES> </META>
Dans ce cas, le fichier /P3P/Policies.xml contient des politiques P3P du site. Ce fichier utilise des définitions de donnée dans le schéma des donnée élémentaire P3P.
9.4.8 – Schéma des données élémentaires P3P
Un schéma est une description d’un ensemble de donnée. P3P a une façon décrire le schéma de donnée pour que le site Web puisse communiquer avec des agents d’utilisateur des données qu’il collecte. Un schéma de donnée est construit par un numéro d’élément de donnée, chaque élément de donnée est une type donnée qu’un service peut collecter. La norme P3P 1.0 défini un schéma de donné s’appelle le schéma des données élémentaires P3P qui décrit un grand nombre d’élément de donnée commun utilisé par le site. Le site peut aussi définir leurs propres nouveaux éléments de donnée.
9.4.9 – Conclusion sur le P3P
Le P3P – Platform for Privacy Preferences est la proposition la plus sophistiquée qui a été faite à partir d’une perspective technique pour augmenter la protection d’intimité sur le Web. Pour obtenir le but de protéger l’intimité des internautes, on ne doit pas beaucoup changer l’infrastructure actuel des sites Web.
10 – Conclusion
Lorsque l’on regarde le sujet du document, on peut facilement trouver que ce sujet est vaste. Il couvrit presque toutes les technologies concernant l’Internet. Et même on doit étudier un peu des lois concernées. Pour les buts commerciaux et personnels, on peut utiliser des technologies, des outils, des connaissances pour obtenir les informations reliées aux autre. Le sujet me demander d’apprendre des causes de la violence de la privée, et comment on peut les arrêter, ou au moins les restreindre.
Il y a plain de choses à faire. Il nous faut des années pour devenir un spécialiste du domaine, car la protection de la vie privée est une partie important de la sécurité sur Internet. Ce document ne nous donne qu’une vue globale sur ceux dont un internaute peut être en face, la messagerie électronique, le spam, les navigateurs, les fenêtres pop-up, …, des informations indésirables, le commerce électronique. Tout est très populaire. Puisqu’il est populaire, il est humain. Protection de quelque chose humaine est importante.
11 – Les vidéos
11.1 - 3 Billion Yahoo Accounts Hacked
The Yahoo breach was a lot worse than we thought, the Equifax ex-CEO sheds light on some questions, disqus was hacked, and Kaspersky is stuck in the middle of debates. All that coming up now on ThreatWire.
11.2 - Introduction to internet security
Cette video en anglais vous présente une introduction à la sécurité Internet. As our lives have moved online we now perform many sensitive or personal transactions over the internet. When we send email, we want to ensure that it not read or modified during transmission. When we purchase goods and services, we want to ensure that our payment information does not fall into the wrong hands. And even when we search the web, we may want to ensure that our explorations remain private and are not visible to our internet service provider. Accomplishing these tasks requires a complex ecosystem combining beautiful mathematical algorithms and systems to establish trust and control who can access what internet resources. Clearly we’re still getting it right few months go by without news of another hack or security vulnerability. But we’re making progress.
11.3 - Why is an IP address not an identity ?
Cette video en anglais vous présente pourquoi une adresse IP n'a pas d'identité. When we exchange data online an internet protocol (IP) address identifies our machine so that it can communicate with other computers. But, for a variety of reasons, that IP address doesn’t necessarily identify us. Although it can in certain cases.
11.4 - What is a browser cookie ?
Cette video en anglais vous présente ce qu'est un cookie. Many authentication schemes require that the browser retain a small piece of information about the user-known as an HTTP cookie. While cookies are often used for authentication, they can be used to record stateful information about a user session, like shopping cart contents. They can also be used to track users over multiple visits to the same website, although this use has caused concern and led to new warnings on sites that you may have noticed.
11.5 - Sniffers les mots de passe

Cette vidéo présente très basiquement comment on peut lire les mots de passe qui passe en claire sur son réseau grâce au Sniffer Wireshark.
11.6 - Le chiffrement Symétrique
Cette vidéo vous présente et vous explique le chiffrement Symétrique.
11.7 - Les clefs asymétriques
Cette vidéo vous présente le fonctionnement des clés asymétriques à l'aide de la clé privée et de la clé publique.
11.8 - Comprendre le Proxy et le Reverse Proxy en 5 minutes
Cette vidéo vous présente et vous explique le rôle du serveur proxy et celui du Reverse Proxy.
11.9 - Why you shouldn't store passwords in your browser.
Secure use of website passwords are just one of the many ways you can protect your company’s assets. From the CEO to the new sales representative, anyone that has access to an organization’s information systems needs a thorough understanding of their effect on cybersecurity. All of the employees at your company are the “human sensors” that must learn to identify the common risks involved in using everyday technology, as well as ways to use it safely, to protect themselves and their organization’s data.
11.10 - Les clés symétriques et asymétriques
Vidéo présentant, de manière très dynamique, les clés symétriques et asymétriques. Cryptographic Algorithms generally fall into one of two different categories, or are a combination of both. Symmetric and Asymmetric.
11.11 - La NSA piratent-ils nos données personnelles ?
Nous ne sommes nulle part à l'abri. NSA ou pirates de l'informatique peuvent en un rien de temps tout savoir de nous, nous écouter, nous observer, nous suivre. Quelle part de vérité se cache derrière ces affirmations ? Rencontre avec des spécialistes de la sécurité informatique. Nous ne sommes nulle part à l'abri. NSA ou pirates de l'informatique peuvent en un rien de temps tout savoir de nous, nous écouter, nous observer, nous suivre. Quelle part de vérité se cache derrière ces affirmations ? Les présentateurs de X:enius, Caro Matzko et Gunnar Mergner, rencontrent à Tübingen des spécialistes de la sécurité informatique. Pour X:enius, ces derniers jouent le rôle des méchants : ils partent à l'abordage de la vie privée de Caro Matsko et découvrent un bon nombre de détails. Les conseils donnés en fin d'émission sont à prendre !
11.12 - Smartphones et vie privée
Un smartphone voyant passer un grand nombre de données personnelles peut révéler beaucoup d’informations sur son utilisateur. Ces informations personnelles sont la plupart du temps exfiltrées vers des serveurs à l’étranger, échappant ainsi à la législation française, pour être stockées, manipulées et échangées avec d’autres acteurs d’une façon totalement inconnue. Il en ressort un besoin de transparence auprès des citoyens et des autorités de régulation qui est pour le moment loin d’être acquis.
11.13 - Le principe du chiffrement par clefs asymétriques
Chiffrer en donnant une clé publique peut parraitre contre-intuitif, depuis des siècles, les humains désirant communiquer de manière cryptée ne pouvaient le faire qu'après rencontre pour convenir du code de chiffrement, depuis les années 1970, grâce à des résultats de mathématique, il est désormais possible de communiquer de manière chiffrer en ne communiquant que des clés publiques ! Bien entendu, celà suppose que le matériel utilisé n'est pas corrompu.
12 – Suivi du document
Création et suivi de la documentation par Nghiem Long PHAN et _SebF
13 – Discussion autour de l’Internet et la vie privée
Vous pouvez poser toutes vos questions, faire part de vos remarques et partager vos expériences à propos de l’Internet et la vie privée. Pour cela, n’hésitez pas à laisser un commentaire ci-dessous :
Commentaire et discussion