Protocole DNS
Sommaire
- 1 – Introduction au protocole DNS
- 2 – Historique du protocole DNS
- 4 – Les zones
- 5 – Recherche de ressources
- 6 – La sécurité
- 7 – Conclusion
- 8 – Les vidéos
- 8.1 - Man in the Middle DNSSpoof
- 8.2 - How are domain names hierarchically organized ?
- 8.3 - How are host names translated to IP addresses ?
- 8.4 - What is the DNS ?
- 8.5 - Detect DNS Delays with Wireshark
- 8.6 - Detect DNS Errors with Wireshark
- 8.7 - DNS Time to live, aging and scavenging
- 8.8 - Protocole DNS - Time to Live
- 8.9 - Protocole DNS - Round Robin
- 8.10 - Protocole DNS - Nslookup et enregistrement MX
- 8.11 - Les types d'enregistrement DNS
- 8.12 - Explication ludique de DNS
- 8.13 - Configuration d'un serveur DNS sous Packet Tracer
- 8.14 - Présentation basique de DNS
- 8.15 - Domain Name System Security Extensions
- 8.16 - Domain Name System par Mr Cisco
- 8.17 - Exercice sur DNS
- 8.18 - DNS, adresses et noms
- 9 – Suivi du document
- 10 – Discussion autour du protocole DNS
- Commentaire et discussion
- Laisser un commentaire
1 – Introduction au protocole DNS
Dans le monde de l’Internet, les machines du réseau sont identifiées par des adresses Ip. Néanmoins, ces adresses ne sont pas très agréables à manipuler, c’est pourquoi, on utilise les noms. L’objectif a alors été de permettre la résolution des noms de domaines qui consiste à assurer la conversion entre les noms d’hôtes et les adresses IP. La solution actuelle est l’utilisation des DNS (Domain Name System) ce que nous allons vous présenter dans ce document.
Le travail présenté ici s’appuie particulièrement sur la RFC 1034 et la RFC 1035. Les RFCs (Request For Comment) sont des documents de l’IETF (Internet Engineering Task Force) qui ont vocation à être les standards d’Internet. Dans une première partie nous ferons une introduction à la notion de Dns, en présentant un bref historique et en nous penchant sur sa structure. Nous nous intéresserons ensuite plus précisément aux serveurs de noms et pour finir nous parlerons du système de recherches des ressources et plus précisément des requêtes Dns.
Vous pouvez regarder de très bonnes vidéos en ligne relatant de manière pédagogique et détaillé le fonctionnement de DNS.
2 – Historique du protocole DNS
Jusqu’en 1984, sur la suite des protocoles TCPIP, la transcription de noms d’hôtes en adresses Internet s’appuyait sur une table de correspondance maintenue par le Network Information Center (NIC), et ce dans un fichier .txt, lequel était transmis par FTP à tous les hôtes. Il n’était à l’époque pas compliqué de stocker les adresses puisque le nombre de machines était très réduit. Par ailleurs, avec la croissance exponentielle d’Internet il a fallu trouver une autre solution, car les problèmes se sont multipliés :
La mise à jour des fichiers : En effet il fallait retransmettre le fichier de mise à jour à tous les hôtes, ce qui encombrait fortement la bande passante du NIC.
L’autonomie des organismes : Avec l’évolution de l’Internet, les architectures ont été transformées, ainsi des organismes locaux ont eu la possibilité de créer leur propres noms et adresses, et ils étaient alors obligés d’attendre que le NIC prenne en compte leurs nouvelles adresses avant que les sites ne puissent être visibles par tous sur Internet. Le souhait était alors que chacun puisse gérer ses adresses avec une certaine autonomie.
Tous ces problèmes ont fait émerger des idées sur l’espace des noms et sa gestion. Les propositions ont été diverses, mais l’une des tendances émergentes a été celle d’un espace de noms hiérarchisé, et dont le principe hiérarchique s’appuierait autant que possible sur la structure des organismes eux-mêmes, et où les noms utiliseraient le caractère « . » pour marquer la frontière entre deux niveaux hiérarchiques.
En 1983-1984, Paul Mockapetris et John Postel proposent et développent une solution qui utilise des structures de base de données distribuée : les Domain Name System, RFCs 882 et 883 devenue obsolète par la RFC 1034. Les spécification des Dns ont été établies en 1987.
| Paul Mockapetris | Jon Postel |
 |
 |
3 – Les formats de l’entête DNS
3.1 – Le transport
3.1.1 – Utilisation d’UDP
Le port serveur utilisé pour l’envoi des datagrammes en Udp est 53. Les datagrammes Dns en Udp sont limités à 512 octets (valeur représentant les données sans l’entête UDP et IP). Les datagramme plus long doivent être tronqué à l’aide du champ Tc.
L’utilisation du protocole UDP n’est pas recommandé pour les transfert de zone, mais uniquement pour les requêtes standards.
3.1.2 – Utilisation de TCP
Le port serveur utilisé pour l’envoi des datagrammes en TCP est 53. Le datagramme inclus alors un champ de deux octets nommé « longueur », il permet de spécifier la la longueur total des données indépendamment de la fragmentation. La longueur est calculé sans les 2 octets de ce même champ.
3.2 – L’entête DNS
Voici la structure de l’entête Dns basé sur 12 octets.
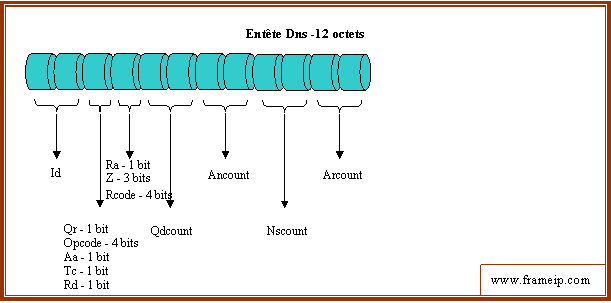
3.2.1 – Id
Codé sur 16 bits, doit être recopié lors de la réponse permettant à l’application de départ de pouvoir identifier le datagramme de retour.
3.2.2 – Qr
Sur un 1 bit, ce champ permet d’indiquer s’il s’agit d’une requête (0) ou d’une réponse (1).
3.2.3 – Opcode
Sur 4 bits, ce champ perme de spécifier le type de requête :
- 0 – Requête standard (Query)
- 1 – Requête inverse (Iquery)
- 2 – Status d’une requête serveur (Status)
- 3-15 – Réservé pour des utilisations futurs
3.2.4 – Aa
Le flag Aa, sur un bit, signifie « Authoritative Answer ». Il indique une réponse d’une entité autoritaire.
3.2.5 – Tc
Le champ Tc , sur un bit, indique que ce message a été tronqué.
3.2.6 – Rd
Le flag Rd, sur un bit, permet de demander la récursivité en le mettant à 1.
3.2.7 – Ra
Le flag Ra, sur un bit, indique que la récursivité est autorisée.
3.2.8 – Z
Le flag Z, sur trois bits, est réservé pour une utilisation futur. Il doit être placé à 0 dans tout les cas. Désormais, cela est divisé en 3 bits : 1 bit pour Z, 1 bit pour AA (Authentificated Answer) qui indique si la réponse et authentifiée, et 1 bit NAD (Non-Authenticated Data) qui indique si les données sont non-authentifiées.
3.2.9 – Rcode
Le champ Rcode, basé sur 4 bits, indique le type de réponse.
- 0 – Pas d’erreur
- 1 – Erreur de format dans la requête
- 2 – Problème sur serveur
- 3 – Le nom n’existe pas
- 4 – Non implémenté
- 5 – Refus
- 6-15 – Réservés
3.2.10 – Qdcount
Codé sur 16 bits, il spécifie le nombre d’entrée dans la section « Question ».
3.2.11 – Ancount
Codé sur 16 bits, il spécifie le nombre d’entrée dans la section « Réponse ».
3.2.12 – Nscount
Codé sur 16 bits, il spécifie le nombre d’entrée dans la section « Autorité ».
3.2.13 – Arcount
Codé sur 16 bits, il spécifie le nombre d’entrée dans la section « Additionnel ».
3.3 – Les RR
La base de données des serveurs de noms (fichier de domaine et fichiers de résolution inverse) est constituée « d’enregistrements de ressources », « Ressource Records » (RRs). Ces enregistrements sont répartis en classes. La seule classe d’enregistrement usuellement employée est la classe Internet (IN). L’ensemble d’informations de ressources associé à un nom particulier est composé de quatre enregistrements de ressources séparés (RR). Voici les différents champs d’un RR que vous pouvez aussi retrouver dans la RFC 1035 au chapitre 3.2.1 :
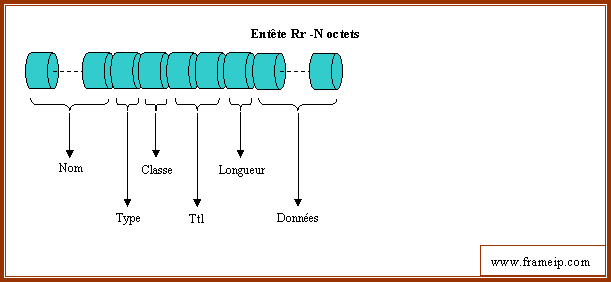
3.3.1 – Nom
Nom du domaine où se trouve le RR. Ce champ est implicite lorsqu’un RR est en dessous d’un autre, auquel cas le champ owner est le même que celui de la ligne précédente.
3.3.2 – Type
Ce champ type, codé sur 16 bits, spécifie quel type de donnée sont utilisés dans le RR. Voici les différents types disponibles:
- Entrée=A et Valeur=01 : Adresse de l’hôte
- Entrée=ns et Valeur=02 : Nom du serveur de noms pour ce domaine
- Entrée=MD et Valeur=03 : Messagerie (obselete par l’entrée MX)
- Entrée=MF et Valeur=04 : Messagerie (obselete par l’entrée MX)
- Entrée=CNAME et Valeur=05 : Nom canonique (Nom pointant sur un autre nom)
- Entrée=SOA et Valeur=06 : Début d’une zone d’autorité (informations générales sur la zone)
- Entrée=MB et Valeur=07 : Une boite à lette du nom de domaine (expérimentale)
- Entrée=MG et Valeur=08 : Membre d’un groupe de mail (expérimentale)
- Entrée=MR et Valeur=09 : Alias pour un site (expérimentale)
- Entrée=NULL et Valeur=10 : Enregistrement à 0 (expérimentale)
- Entrée=WKS et Valeur=11 : Services Internet connus sur la machine
- Entrée=PTR et Valeur=12 : Pointeur vers un autre espace du domaine (résolution inverse)
- Entrée=HINFO et Valeur=13 : Description de la machine
- Entrée=MINFO et Valeur=14 : Groupe de boite à lettres
- Entrée=MX et Valeur=15 : Mail exchange (Indique le serveur de messagerie. Voir [RFC-974] pour plus de détails
- Entrée=TXT et Valeur=16 : Chaîne de caractère
3.3.3 – Classe
Une valeur encodée sur 16 bits identifiant une famille de protocoles ou une instance d’un protocole. Voici les classes de protocole possible :
- Entrée=In et Valeur=01 : Internet
- Entrée=Cs et Valeur=02 : Class Csnet (obselete)
- Entrée=Ch et Valeur=03 : Chaos (chaosnet est un ancien réseau qui historiquement a eu une grosse influence sur le développement de l’Internet, on peut considérer à l’heure actuelle qu’il n’est plus utilisé)
- Entrée=Hs et Valeur=04 : Hesiod
3.3.4 – TTL
C’est la durée de vie des RRs (32 bits, en secondes), utilisée par les solveurs de noms lorsqu’ils ont un cache des RRs pour connaître la durée de validité des informations du cache.
3.3.5 – Longueur
Sur 16 bits, ce champ indique la longueur des données suivantes.
3.3.6 – Données
Données identifiant la ressource, ce que l’on met dans ce champs dépend évidemment du type de ressources que l’on décrit.
- A : Pour la classe IN, une adresse IP sur 32 bits. Pour la classe CH, un nom de domaine suivi d’une adresse octale Chaotique sur 16 bits.
- Cname : un nom de domaine.
- Mx : une valeur de préférence sur 16 bits (la plus basse possible) suivie d’un nom d’hôte souhaitant servir d’échangeur de courrier pour le domaine de l’owner.
- Ptr : Une adresse IP sous forme d’un nom.
- Ns : Un nom d’hôte.
- Soa : Plusieurs champs.
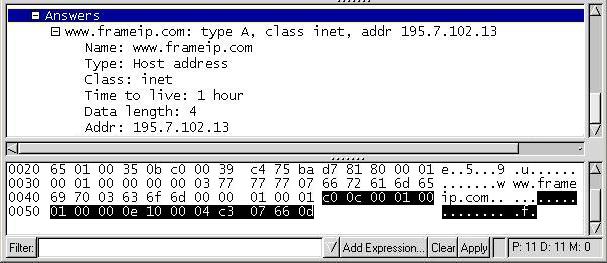
Voici un exemple montrant les différents champs saisies par Ethereal :
4 – Les zones
4.1 – Structure arborescente de l’espace de noms
Le service DNS utilise la gestion hiérarchique des noms. On distingue deux domaines pour le classement des noms.
4.1.1 – Les domaines géographiques (Codes ISO 3166)
| .ac – Ascension .ad – Andorre .ae – Emirats Arabes Unis .af – Afganistan .ag – Antigua And Barbuda .ai – Anguilla .al – Albania .am – Arménie .an – Netherlands Antilles .ao – Angola .aq – Antartique .ar – Argentine .as – American Samoa .at – Autriche .au – Australie .aw – Aruba .az – Azerbaijan .ba – Bosnie Herzégovine .bb – Barbades .bd – Bangladesh .be – Belgique .bf – Burkina Faso .bg – Bulgarie .bh – Bahrain .bi – Burundi .bj – Benin .bm – Bermudes .bn – Brunei Darussalam .bo – Bolivie .br – Brésil .bs – Bahamas .bt – Bhutan .bv – Bouvet Island .bw – Botswana .by – Belarus .bz – Belize .ca – Canada .cc – Cocos (Keeling) Islands .cd – République du Congo .cf – République d’Afrique Centrale .cg – Congo .ch – Suisse .ci – Cote d’Ivoire .ck – Iles Cook .cl – Chili .cm – Cameroun .cn – Chine .co – Colombie .cr – Costa Rica .cu – Cuba .cv – Cap Vert .cx – Christmas Island .cy – Chypre .cz – République Tchèque .de – Allemagne .dj – Djibouti .dk – Danmark .dm – Dominica .do – République Dominicaine .dz – Algérie .ec – Equateur .ee – Estonie .eg – Egypte .eh – Sahara occidental .er – Erytrée .es – Espagne .et – Ethiopie .fi – Finlande .fj – Fiji .fk – Iles Fakland (Malouines) .fm – Micronesie (Etat Fédéral) .fo – Iles Faroe .fr – France .fx – France Métropoliotaine .ga – Gabon .gb – Grande Bretagne .gd – Grenade .ge – Géorgie .gf – Guyane Française .gg – Guernesey .gh – Ghana .gi – Gibraltar .gl – Groenland |
.gm – Gambie .gn – Guinée .gp – Guadeloupe .gq – Guinéee Equatoriale .gr – Grèce .gs – South Georgia and the South Sandwich Islands .gt – Guatemala .gu – Ile de Guam .gw – Guiné-Bissau .gy – Guyane .hk – Hong Kong .hm – Heard and McDonald Islands .hn – Honduras .hr – Croatie/Hrvatska .ht – Haiti .he – Hongrie .hu – Hongarie .id – Indonésie .ie – Irelande .il – Israel .im – Isle of Man .in – Inde .io – Territoire Anglais de l’Océan Indien .iq – Irak .ir – Iran (Islamic Republic of) .is – Islande .it – Italie .je – Jersey .jm – Jamaïque .jo – Jordanie .jp – Japon .ke – Kenya .kg – Kyrgyzstan .kh – Cambodge .ki – Kiribati .km – Iles Comores .kn – Saint Kitts and Nevis .kp – République Démocratique populaire de Corée .kr – République de Corée .kw – Koweit .ky – Iles Cayman .kz – Kazakhstan .la – République Démocratique populaire du Laos .lb – Liban .lc – Sainte Lucie .li – Liechtenstein .lk – Sri Lanka .lr – Liberia .ls – Lesotho .lt – Lituanie .lu – Luxembourg .lv – Latvia .ly – Libyan Arab Jamahiriya .ma – Maroc .mc – Monaco .md – République de Moldavie .mg – Madagascar .mh – Iles Marshall .mk – Macédoine, ex République Yougoslave .ml – Mali .mm – Myanmar .mn – Mongolie .mo – Macao .mp – Iles Mariannes du Nord .mq – Martinique .mr – Mauritanie .ms – Montserrat .mt – Malte .mu – Ile Maurice .mv – Maldives .mw – Malawi .mx – Mexique .my – Malaisie .mz – Mozambique .na – Namibie .nc – Nouvelle Calédonie .ne – Niger .nf – Iles Norfolk .ng – Nigeria .ni – Nicaragua .nl – Hollande .no – Norvège |
.np – Nepal .nr – Nauru .nu – Niue .nz – Nouvelle Zélande .om – Oman .pa – Panama .pe – Pérou .pf – Polynésie Française .pg – Papouasie Nouvelle Guinée .ph – Philippines .pk – Pakistan .pl – Pologne .pm – Saint Pierre et Miquelon .pn – Pitcairn Island .pr – Porto Rico .ps – Territoires Palestiniens .pt – Portugal .pw – Palau .py – Paraguay .qa – Qatar .re – L’Ile de la Réunion .ro – Roumanie .ru – Fédération Russe .rw – Rwanda .sa – Arabie Saoudite .sb – Iles Salomon .sc – Seychelles .sd – Soudan .se – Suède .sg – Singapour .sh – Sainte Hélène .si – Slovanie .sj – Svalbard and Jan Mayen Islands .sk – Slovaquie .sl – Sierra Leone .sm – San Marino .sn – Sénégal .so – Somalie .sr – Surinam .st – Sao Tome and Principe .sv – Salvador .sy – Syrie .sz – Swaziland .tc – Iles Turques et Caicos .td – Tchad .tf – Territoire Français du Sud .tg – Togo .th – Thailande .tj – Tajikistan .tk – Tokelau .tm – Turkmenistan .tn – Tunisie .to – Iles Tonga .tp – Timor Oriental .tr – Turquie .tt – Trinité et Tobago .tv – Tuvalu .tw – Taiwan .tz – Tanzanie .ua – Ukraine .ug – Ouganda .uk – Royaume Uni .um – US Minor Outlying Islands .us – United States .uy – Uruguay .uz – Uzbekistan .va – Vatican .vc – Iles Grenadines et St Vincent .ve – Vénézuela .vg – Iles Vierges Anglaises .vi – Iles Vierges Américaines .vn – VietNam .vu – Vanuatu .wf – Iles de Wallis et Futuna .ws – Samoa .ye – Yemen .yt – Mayotte .yu – Yougoslavie .za – Afrique du sud .zm – Zambie .zw – Zimbabwe |
4.1.2 – Les domaines génériques
Cette liste est définie par la RFC 1591 – Domain Name System Structure and Delegation
- .com – Commerciaux
- .edu – Organismes d’éducation américaine
- .net – Organismes de gestion de réseaux
- .org – Organismes non-commerciaux
- .int – Organismes internationaux
- .gov – Organismes gouvernementaux USA
- .mil – Organismes militaires USA
- .arpa – Transition ARPAnet-> Internet + traduction inverse
L’arborescence des noms de domaine est constituée :
- d’une racine
- de noeud identifiés par des labels dont les informations sont stockées dans une base de données
Les labels portés par les noeuds font entre 0 et 63 octets, sachant que l’identifiant de longueur zéro est réservé à la racine. Deux noeuds » frère » ne peuvent pas porter le même identifiant, néanmoins, deux noeuds peuvent avoir le même label dans le cas où il n’on aucun lien de » fratrie « . Le nom de domaine d’un noeud est constitué des identifiants situés entre ce noeud à la racine de l’arborescence. Lorsqu’un utilisateur doit entrer un nom de domaine, la longueur de chaque identifiant est omise et les identifiants devront être séparés par des points (« . »). Un nom de domaine complet atteignant toujours la racine, la forme écrite exacte de tout domaine entièrement qualifié se termine par un point. Nous utiliserons cette propriété pour distinguer les cas :
- d’une chaîne de caractères représentant un nom de domaine complet (souvent appelé « absolu » ou « entièrement qualifié »). Par exemple, « www.FRAMEIP.COM »
- d’une chaîne de caractères représentant les premiers identifiants d’un nom de domaine incomplet, et devant être complété par l’application locale avec un complément absolu (expression appelée « relative »). Par exemple, « www », à utiliser relativement au domaine FRAMEIP.COM.
4.2 – Formation des zones DNS
La base de données est divisée en sections appelées zones, lesquelles sont distribuées sur l’ensemble des serveurs de noms. De plus, elle est divisée selon deux méthodes : en classes et par « découpage » de l’espace des noms de domaines.
La partition en classes est assez simple. La base de données est organisée, déléguée, et maintenue séparément pour chacune des classes. Comme par convention, l’espace de noms est identique quel que soit la classe, la séparation par classe peut conduire à voir l’espace de domaines comme un tableau d’arbres de noms parallèles. Notez que les données attachées aux noeuds des arbres seront différentes dans chaque arbre.
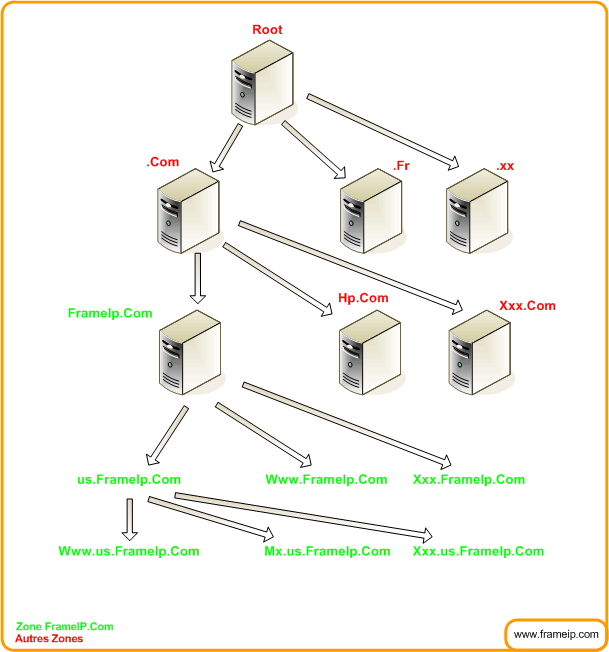
4.3 – Principes des zones
Dans une classe, des « coupes » dans l’espace de noms peuvent être faites entre deux noeuds adjacents quelconques. Un fois toutes les coupes définies, chaque groupe de noeuds interconnectés devient une zone indépendante. La zone est alors définie comme étant la « sphère d’autorisation » pour tout nom à l’intérieur de la zone. Notez que les « coupes » dans l’espace de noms peuvent être à des endroits différents de l’arbre suivant la classe, les serveurs de noms associés peuvent être différents, etc.
Ces règles signifient que chaque zone doit avoir au moins un noeud, et donc un nom de domaine, pour lequel il est « autorisé », et que tous les noeuds d’une zone particulière sont connectés. Du fait de la structure d’arbre, chaque zone contient un noeud « de plus haut niveau » qui est plus proche de la racine que tous les autres noeuds de cette zone. Le nom de ce noeud est souvent utilisé pour identifier la zone elle-même.
Selon ce concept, il est possible, bien que pas forcément utile, de découper l’espace de noms de telle façon que chaque nom de domaine se retrouve dans une zone séparée ou au contraire que tous les noeuds se retrouvent dans une zone unique.
4.4 – Description techniques pour les zones
Les données qui décrivent chaque zone sont organisées en quatre parties :
- Les données générales sur chaque noeud de la zone
- Les données qui définissent le noeud supérieur de la zone
- Les données qui décrivent les sous-zones
- Les données qui permettent d’accéder aux serveurs de noms qui gèrent les sous-zones
Toutes ces données sont stockées dans des RRs, donc une zone peut être entièrement décrite par un jeu de RRs. Les informations sur des zones entières peuvent donc être transmises d’un serveur à l’autre, tout simplement en échangeant ces RRs.
Les plus importants des RRs sont ceux qui décrivent le noeud principal d’une zone. Ils sont de deux sortes : des RRs qui répertorient l’ensemble des serveurs de noms de la zone, et un RR de type SOA qui décrit les paramètres de gestion de la zone.
Les RRs contenant des informations sur les sous zones sont de type NS. Il faut des informations pour connaître l’adresse d’un serveur dans la sous zone, ceci pour pouvoir y accéder. Ce genre de données est conservé dans d’autres RRs. Tout est fait pour que dans la structure en zones, toute zone puisse disposer localement de toutes les données nécessaires pour communiquer avec les serveurs de noms de chacune de ses sous-zones.
4.5 – Type de serveurs et autorités
Par le découpage en zone on a donc trois types de serveurs de noms.
4.5.1 – Le serveur primaire
Le serveur primaire est serveur d’autorité sur sa zone : il tient à jour un fichier appelé « fichier de zone », qui établit les correspondances entre les noms et les adresses IP des hosts de sa zone. Chaque domaine possède un et un seul serveur primaire.
4.5.2 – Le serveur secondaire
Un serveur de nom secondaire obtient les données de zone via le réseau, à partir d’un autre serveur de nom qui détient l’autorité pour la zone considérée. L’obtention des informations de zone via le réseau est appelé transfert de zone (voir partie 2.4). Il est capable de répondre aux requêtes de noms IP (partage de charge), et de secourir le serveur primaire en cas de panne. Le nombre de serveurs secondaires par zone n’est pas limité. Ainsi il y a une redondance de l’information. Le minimum imposé est un serveur secondaire et le pré requis mais pas obligatoire est de le situer sur un segment différent du serveur primaire.
Un serveur qui effectue un transfert de zone vers un autre serveur est appelé serveur maître. Un serveur maître peut être un serveur primaire ou un serveur secondaire. Un serveur secondaire peut disposer d’une liste de serveurs maîtres (jusqu’à dix serveurs maîtres). Le serveur secondaire contacte successivement les serveurs de cette liste, jusqu’à ce qu’il ait pu réaliser son transfert de zone.
4.5.3 – Le serveur cache
Le serveur cache ne constitue sa base d’information qu’à partir des réponses des serveurs de noms. Il inscrit les correspondances nom / adresse IP dans un cache avec une durée de validité limitée (TTL) ; il n’a aucune autorité sur le domaine : il n’est pas responsable de la mise à jour des informations contenues dans son cache, mais il est capable de répondre aux requêtes des clients DNS.
De plus on peut distinguer les serveurs racine : ils connaissent les serveurs de nom ayant autorité sur tous les domaines racine. Les serveurs racine connaissent au moins les serveurs de noms pouvant résoudre le premier niveau (.com, .edu, .fr, etc.) C’est une pierre angulaire du système Dns : si les serveurs racine sont inopérationnels, il n’y a plus de communication sur l’Internet, d’où multiplicité des serveurs racines (actuellement il y en a 14). Chaque serveur racine reçoit environ 100 000 requêtes par heure.
Un serveur de nom, en terme de physique, peux très bien jouer le rôle de plusieurs de ces fonctions. On trouvera par exemple, beaucoup d’entreprise qui héberge leurs domaine sur le serveur Dns primaire servant aussi de cache pour les requêtes sortantes des utilisateurs interne.
4.6 – La diffusion des modifications
« Le transfert de zones »
Pour chaque zone Dns, le serveur servant de référence est le Dns maître ou Dns primaire. Les Dns esclaves ou secondaires servant cette zone vont récupérer les informations du Dns maître. Cette récupération d’information est appelée transfert de zone. Seuls les Dns secondaires ont besoin d’être autorisés à effectuer cette opération, mais assez souvent aucune restriction n’est présente. Ceci permettant à n’importe qui de se connecter via nslookup et d’utiliser l’argument ls -d permettant l’affichage du contenu d’une zone.
Lorsque des changements apparaissent sur une zone, il faut que tous les serveurs qui gèrent cette zone en soient informés. Les changements sont effectués sur le serveur principal, le plus souvent en éditant un fichier. Après avoir édité le fichier, l’administrateur signale au serveur qu’une mise à jour a été effectuée, le plus souvent au moyen d’un signal (SIGINT). Les serveurs secondaires interrogent régulièrement le serveur principal pour savoir si les données ont changé depuis la dernière mise à jour. Ils utilisent un numéro constitué de la date au format américain: année, mois, jour; version du jour, il est donc toujours incrémenté. Donc pour la mise a jour ils comparent le champ SERIAL du RR SOA de la zone donnée par le serveur principal contenant le numéro à celui qu’ils connaissent. Si ce numéro a augmenté, ils chargent les nouvelles données.
4.7 – Les pannes
Lorsqu’un serveur primaire est indisponible, le serveur secondaire ne reçoit pas de réponse à ses interrogations sur le numéro de version du fichier de zone. Il continue ses tentatives jusqu’à expiration de la validité des enregistrements de son fichier de zone (‘Expire Time’). Lorsqu’un serveur primaire redevient disponible, aucun mécanisme de synchronisation entre le fichier de zone des serveurs secondaires et celui du serveur primaire n’a été normalisé.
5 – Recherche de ressources
5.1 – Les Résolveurs
Les « résolveurs » sont des programmes qui interfacent les applications utilisateur aux serveurs de noms de domaines. En effet, ce n’est pas l’utilisateur qui effectue les requêtes directement. Dans le cas le plus simple, un résolveur reçoit une requête provenant d’une application (ex., applications de courrier électronique, Telnet, FTP) sous la forme d’un appel d’une fonction de bibliothèque, d’un appel système etc., et renvoie une information sous une forme compatible avec la représentation locale de données du système.
Le résolveur est situé sur la même machine que l’application recourant à ses services, mais devra par contre consulter des serveurs de noms de domaines sur d’autres hôtes. Comme un résolveur peut avoir besoin de contacter plusieurs serveurs de noms, ou obtenir les informations directement à partir de son cache local, le temps de réponse d’un résolveur peut varier selon de grandes proportions, depuis quelques millisecondes à plusieurs secondes.
L’une des raisons les plus importantes qui justifient l’existence des résolveurs est d’éliminer le temps d’acheminement de l’information depuis le réseau, et de décharger simultanément les serveurs de noms, en répondant à partir des données cachées en local. Il en résulte qu’un cache partagé entre plusieurs processus, utilisateurs, machines, etc., sera incomparablement plus efficace qu’une cache non partagé.
5.2 – Les Requêtes
La principale activité d’un serveur de noms est de répondre aux requêtes standard. La requête et sa réponse sont toutes deux véhiculées par un message standardisé décrit dans la RFC 1035. La requête contient des champs QTYPE, QCLASS, et QNAME, qui décrivent le(s) type(s) et les classes de l’information souhaitée, et quel nom de domaine cette information concerne. Les requêtes sont des messages envoyés aux serveurs de noms en vue de consulter les données stockées par le serveur. Par exemple avec Internet, on peut utiliser aussi bien UDP que TCP pour envoyer ces requêtes.
5.2.1 – Structure des requêtes
Parmi les champs fixes on trouve 4 bits très importants appelé code d’opération (OPCODE). Le code d’opération permet de donner des informations sur la nature du message (requête, réponse, …). Les quatre possibilités sont :
- Question, Contient la question (nom d’hôte ou de domaine sur lequel on cherche des renseignements et type de renseignements recherchés).
- Answer, Contient les RRs qui répondent à la question.
- Authority, Contient des RRs qui indiquent des serveurs ayant une connaissance complète de cette partie du réseau.
- Additional, Contient des RRs supplémentaires pouvant être utiles pour exploiter les informations contenues dans les autres sections.
Voici un exemple de requête où l’on souhaite connaître le nom du serveur de courrier s’occupant de frameip.com :
- Header : OPCODE=SQUERY
- Question : QNAME=ISI.EDU., QCLASS=IN, QTYPE=MX
- Answer : Vide
- Authotity : Vide
- Additionnal : Vide
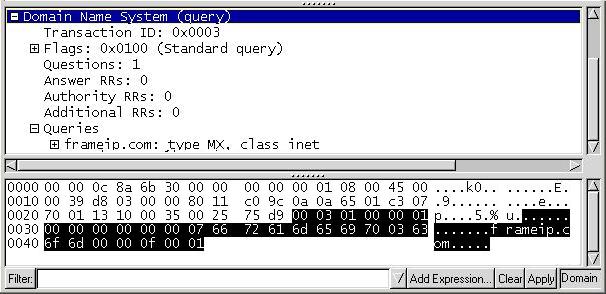
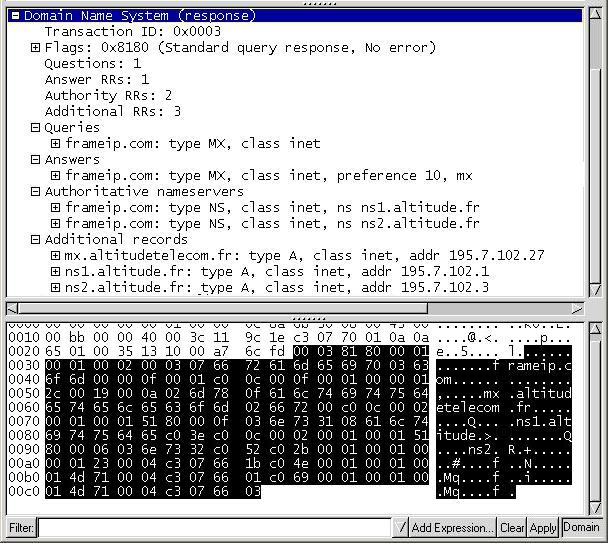
La réponse obtenue est :
- Header : OPCODE=SQUERY, RESPONSE, AA
- Question : QNAME=ISI.EDU., QCLASS=IN, QTYPE=MX
- Answer : ISI.EDU MX 10 VENERA.ISI.EDU MX 10 VAXA.ISI.EDU
- Authotity : Vide
- Additionnal : VENERA.ISI.EDU A 128.9.0.32 A 10.1.0.52 VAXA.ISI.EDU A 10.2.0.27 A 128.9.0.33
5.2.2 – Le mode Itératif
Ce mode est le plus simple du point de vue du serveur. Les serveur répondent directement à la requête sur la base seule de ses informations locales. La réponse peut contenir la réponse demandée, ou bien donne la référence d’un autre serveur qui sera « plus susceptible » de disposer de l’information demandée. Il est important que tous les serveurs de noms puissent implémenter ce mode itératif et désactive la fonction de récursivité.
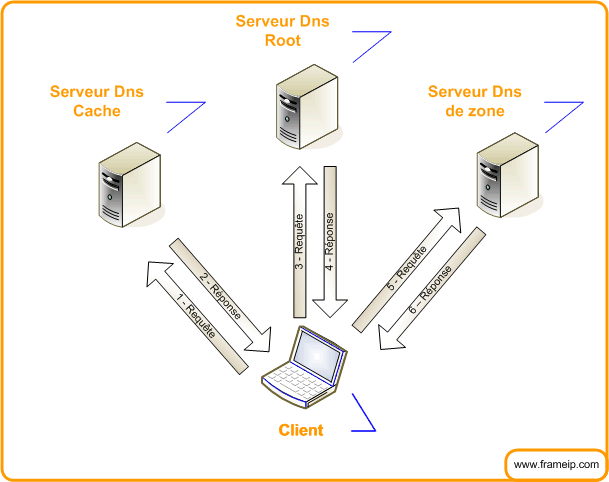
Les avantages d’une résolution itérative :
- Dans le cas d’une implémentation simplifiée d’un résolveur qui ne sait exploiter d’autres réponses qu’une réponse directe à la question.
- Dans le cas d’une requête qui doit passer à travers d’autres protocoles ou autres « frontières » et doit pouvoir être envoyée à un serveur jouant le rôle d’intermédiaire.
- Dans le cas d’un réseau dans lequel intervient une politique de cache commun plutôt qu’un cache individuel par client.
Le service non-récursif est approprié si le résolveur est capable de façon autonome de poursuivre sa recherche et est capable d’exploiter l’information supplémentaire qui lui est envoyée pour l’aider à résoudre son problème.
5.2.3 – Le mode Récursif
Le mode récursif est plus simple du point de vue du client. Dans ce mode, le premier serveur prend le rôle de résolveur.
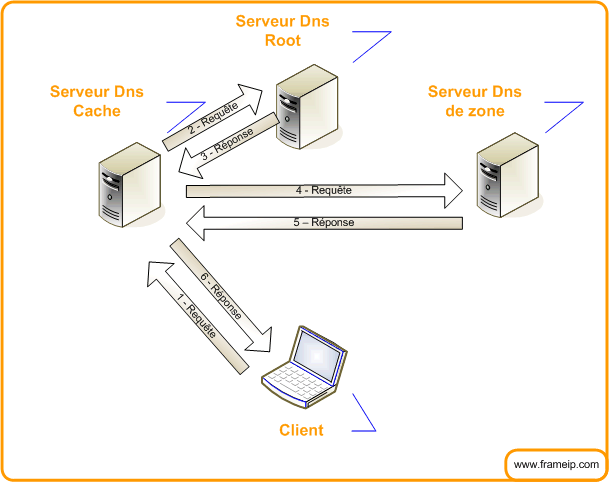
L’utilisation du mode récursif est limité aux cas qui résultent d’un accord négocié entre le client et le serveur. Cet accord est négocié par l’utilisation de deux bits particuliers des messages de requête et de réponse :
Le bit Ra (Récursion admissible), est marqué ou non par le serveur dans toutes les réponses. Ce bit est marqué si le serveur accepte à priori de fournir le service récursif au client, que ce dernier l’ait demandé ou non. Autrement dit, le bit RA signale la disponibilité du service plutôt que son utilisation.
Les requêtes disposent d’un bit Rd (pour « récursion désirée »). Ce bit indique que le requérant désire utiliser le service récursif pour cette requête. Les clients peuvent demander le service récursif à n’importe quel serveur de noms, bien que ce service ne puisse leur être fourni que par les serveurs qui auront déjà marqué leur bit RA, ou des serveurs qui auront donné leur accord pour ce service par une négociation propriétaire ou tout autre moyen hors du champ du protocole DNS.
Le mode récursif est mis en oeuvre lorsqu’une requête arrive avec un bit Rd marqué sur un serveur annonçant disposer de ce service, le client peut vérifier si le mode récursif a été utilisé en constatant que les deux bits Ra et Rd ont été marqués dans la réponse.
Notez que le serveur de noms ne doit pas utiliser le service récursif s’il n’a pas été explicitement demandé par un bit RD, car cela interfère avec la maintenance des serveurs de noms et de leurs bases de données. Lorsque le service récursif est demandé et est disponible, la réponse récursive à une requête doit être l’une des suivantes :
- La réponse à la requête, éventuellement préfacée par un ou plusieurs RR CNAME qui indiquent les alias trouvés pendant la recherche de la réponse.
- Une erreur de nom indiquant que le nom demandé n’existe pas. Celle-ci peut inclure des RR CNAME qui indiquent que la requête originale pointait l’alias d’un nom qui n’existe pas.
- Une indication d’erreur temporaire.
- Si le service récursif n’est pas requis, ou n’est pas disponible, la réponse non-récursive devra être l’une des suivantes :
- Une réponse d’erreur « autorisée » indiquant que le nom n’existe pas.
- Une indication temporaire d’erreur.
- Une combinaison :
- Des RR qui répondent à la question, avec indication si les données sont extraites d’une zone ou d’un cache.
- D’une référence à un serveur de noms qui gère une zone plus « proche » du nom demandé que le serveur qui a été contacté.
- Les RR que le serveur de nom pense être utile au requérant pour continuer sa recherche.
5.2.4 – Exemple de résolution de noms
Nous allons voir avec un exemple comment se fait le parcours de l’arborescence pour la résolution de noms. On prend par exemple l’adresse suivante : www.frameip.com Il faut alors :
- Trouver le NS de la racine
- Interroger pour trouver le NS des .com
- Poser la question finale au NS de frameip.com qui identifiera l’entrée www
5.3 – Les Requêtes inverses
5.3.1 – Fonctionnement
Dans le cas d’une requête inverse, le solveur envoie une demande à un serveur de noms afin que celui-ci renvoie le nom d’hôte associé à une adresse Ip connue. C’est utile surtout pour des questions de sécurité, pour savoir avec qui on échange. La mise en place de la résolution inverse est un peu plus compliquée, car l’adressage par nom est basé sur la notion de domaine qui souvent n’a rien à voir avec la structure des adresses Ip. Par conséquent, seule une recherche approfondie portant sur tous les domaines peut garantir l’obtention d’une réponse exacte. Deux moyens existent pour convertir une adresse IP en nom d’hôte : l’usage de requêtes Dns inversées (Au sens Opcode=Iquery où Iquery = 1) ou les requêtes Dns de type Ptr (Classe IN et Opcode=Query).
En effet, dans le premier cas, on envoie un message Dns contenant une réponse et on demande toutes les questions pouvant conduire à cette réponse, alors que les requêtes Ptr posent la question de façon explicite : Qui est l’adresse a.b.c.d ?
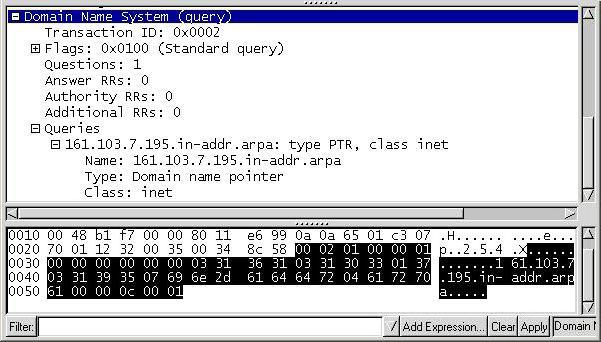
Une requête Dns inversée a la particularité d’avoir le champ Question vide, et de contenir une entrée dans le champ Answer. Pour que le serveur Dns comprenne le sens de la requête, le champ Opcode des entêtes du message Dns doit être à la valeur Iquery. Voici une représentation extraite de la RFC 1035 :
- Header : OPCODE=IQUERY, ID=997
- Question : Vide
- Answer : « ANYNAME » A IN 10.1.0.52
- Authotity : Vide
- Additionnal : Vide
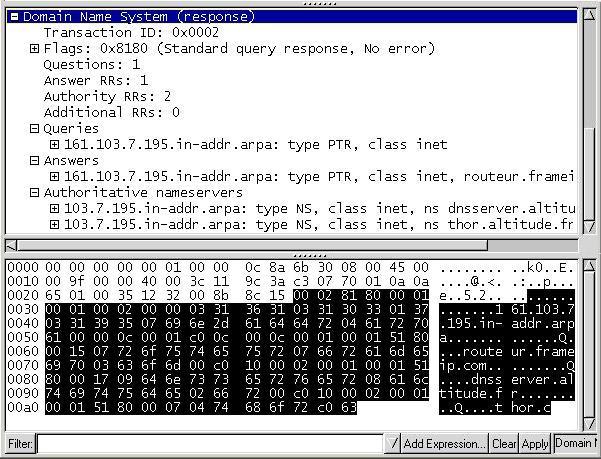
Pour répondre aux requêtes inverses en évitant des recherches exhaustives dans tous les domaines, un domaine spécial appelé in-addr.arpa a été créé. Une fois le domaine in-addr.arpa construit, des enregistrements de ressources spéciaux sont ajoutés pour associer les adresses IP au noms d’hôte qui leur correspondent. Il s’agit des enregistrements pointeurs (PTR), ou enregistrements de références. Par exemple pour connaître le nom de la machine dont l’adresse est 137.194.206.1, on envoie une requête dont la question contient QNAME=1.206.194.137.IN-ADDR.ARPA.
5.3.2 – Exemple
Ligne de commande permettant d’établir la requête
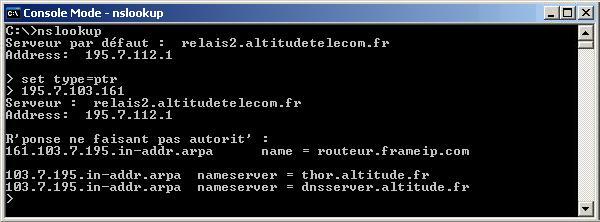
Capture du datagramme Query
Capture du datagramme Answer
6 – La sécurité
6.1 – Fragilité
Sans le Dns, la majorité des applications d’Internet s’arrêtent! De plus le Dns est souvent la cible favorite des dénis de service (Dos) des pirates. Il y a aussi un exemple simple avec le système de requêtes inversées vu précédemment qui entraîne une fuite d’information (ceci représentant la partie découverte de l’attaque). Jusqu’ici, nous n’avons utilisés les requêtes Dns inversées que pour faire la correspondance entre une adresse Ip et l’hostname associé (Requête de classe IN et de type A). Or, nous pouvons faire des recherches inversées sur d’autres types de ressources. Par exemple, nous pourrions émettre une requête inverse au sujet des champs HINFO1 pour se chercher toutes les machines tournant sous une version vulnérable d’un certain système d’exploitation. En effet, le champs Hinfo est sensé contenir le type et version du Système d’Exploitation de la machine.
6.2 – Sécurisation
Les normes de sécurisation du DNS portent sur la certification de l’origine des données, l’authentification des transactions et des requêtes. Elles ne portent pas sur la confidentialité des informations : les données échangées ne sont pas chiffrées avant d’être transportées par le réseau et n’apporte aucune protection aux entêtes des messages DNS, ou aux trames de commandes (requêtes DNS).
La sécurisation du Dns doit assurer l’authentification d’une transaction, c’est à dire que le Resolver reçoit une réponse provenant bien du serveur à qui il a envoyé une requête, qu’il s’agit de la réponse correspondant effectivement à sa requête, que la trame n’a pas été « diddled » (dupé) lors de son transport par le réseau.
L’authentification de transaction est assurée par le rajout d’un « Enregistrement de Signature » (SIG RR) à la fin de la trame de réponse. La signature est créée à partir d’une concaténation entre la réponse du serveur et la requête du client. La clef privée utilisée pour la signature appartient au serveur qui émet le message signé, et non à la zone. Les clefs publiques utilisées dans les mécanismes de sécurisation du Dns sont contenues dans des « Enregistrements de Clefs » (Key RR) stockés dans la base de données du Dns. Ces clefs publiques peuvent être destinées à une zone, à un host ou autre. Un KEY RR est authentifié par un SIG RR comme n’importe quel autre enregistrement.
7 – Conclusion
Le système de gestion de noms DNS est efficace et unificateur. De plus, comme tous les systèmes cruciaux d’Internet, il y a au moins une implémentation efficace et gratuite. C’est portable et très complet.
Bind est le gestionnaire de DNS le plus connu et probablement un des plus complets. Il fonctionne sous Unix et Windows. Nouvelle syntaxe des fichiers de configuration sur la dernière version 9 avec un système de log flexible par catégories, une liste d’accès par adresse Ip sur les requêtes, transfert de zones et mises a jours pour chaque zone, transfert de zones plus efficaces et enfin des meilleures performances pour les serveurs gérant des milliers de zones.
Récemment est apparue le DnsSEC. DnsSEC est un ensemble de protocoles utilisant de la cryptographie symétrique et/ou asymétrique incorporant un système de stockage et de publication des clés publiques. Ainsi, il permet de résoudre les différents problèmes de sécurité lors des transferts de zone, des mises à jour (update dynamique par exemple) et de rendre inopérant le Dns spoofing (détournement de flux entre deux machines à l’avantage du pirate). A ces nouveautés s’ajoute la compatibilité avec IPv6 et surtout l’interopérabilité des deux systèmes d’adressages, ce qui en fait un système très complexe. Les dernières versions de Bind 9 incorporent ces dernières possibilités, mais il faudrait un déploiement à l’échelle mondiale pour que le système soit réellement utilisable.
8 – Les vidéos
8.1 - Man in the Middle DNSSpoof
The LAN Turtle is a covert Systems Administration and Penetration Testing tool providing stealth remote access, network intelligence gathering, and man-in-the-middle monitoring capabilities.
8.2 - How are domain names hierarchically organized ?
Cette video en anglais vous présente l'organisation hiérarchiqe des noms de domaine. Just like IP addresses, domain names are also hierarchically allocated and organized. In a somewhat confusing twist, unlike an IP address where the prefix is on the left and identifies the organization, for a domain name the part that identifies an organization is on the right it’s the postfix. Nevertheless, once you learn how to parse domain names they make a lot of sense.
8.3 - How are host names translated to IP addresses ?
Cette video en anglais vous présente le passage d'un nom d'hôte à une adresse IP. Every time you use a host name in a URL, URI, email address, or any other way, it must be translated to an IP address. The packets exchange by computers on the internet are routed and addressedonly by IP addresses, not at all using the human readable names created for our convenience.
8.4 - What is the DNS ?
Cette video en anglais vous présente de qu'est DNS (Domain Name Service). Domain name to IP address translation happens all the time on the internet. The core internet service responsible for translating machine names to numbers is the domain name service, also known as DNS. DNS can be thought of as a distributed phone book in which computers all over the world regularly exchange information about correct translations. However, DNS is a bit more complicated than a phone book in ways that have important implications for internet performance.
8.5 - Detect DNS Delays with Wireshark
Cette vidéo en anglais vous montre comment detecter et analyser le delay dans le protocole DNS (Domain Name System). Use the dns.time field to quickly locate slow DNS responses in your trace files.
8.6 - Detect DNS Errors with Wireshark
Cette vidéo en anglais vous montre comment detecter et analyser les erreurs dans le protocole DNS (Domain Name System). Create a filter expression button based on the dns.flags.rcode field to quickly locate DNS errors in your trace files.
8.7 - DNS Time to live, aging and scavenging
The DNS settings looked at in this video determine how long DNS records remain on the DNS server or in the DNS cache. DNS supports automatic removal of DNS records from the database if the appropriate options have been configured. This video looks at how to configure those options and the effects this can have on your network if the settings are not managed correctly.
8.8 - Protocole DNS - Time to Live
Cette vidéo en Anglais présente le TTL (Time To Live) du protocole DNS (Domain Name System).
8.9 - Protocole DNS - Round Robin
Cette vidéo en Anglais présente le Round Robin DNS (Domain Name System). Round Robin DNS provides limited load balancing. In this video, Senior Technical Instructor Doug Bassett shows how to configure Round Robin DNS using A and CNAME records.
8.10 - Protocole DNS - Nslookup et enregistrement MX
Cette vidéo en Anglais présente DNS (Domain Name System) à travers la commande Nslookup et l'enristrment de type MX. In this video, Senior MS Instructor Doug Bassett provides valuable information on verifying DNS information using Nslookup.
8.11 - Les types d'enregistrement DNS
Cette vidéo en Anglais présente les différents type d'enregistrement de DNS (Domain Name System). In order to find resources on the network, computers need a system to look up the location of resources. This video looks at the DNS records that contain information about resources and services on the network. The client can request these records from a DNS server in order to locate resources like web sites, Active Directory Domains and Mail Servers just to name a few.
8.12 - Explication ludique de DNS
Cette vidéo en Anglais présente et explique de manière ludique le fonctionnement de DNS (Domain Name System). Learn the ins and outs of how the Domain Name System (known as DNS by the cool kids), takes a name like dnsmadeeasy.com and translates it into an IP address to find content on the web.
8.13 - Configuration d'un serveur DNS sous Packet Tracer

Cette vidéo vous présente à quoi sert un serveur DNS (Domain Name System) et vous présente un paramétrage sous Packet Tracer.
8.14 - Présentation basique de DNS
Vidéo présentant les bases du fonctionnemet de DNS (Domain Name System). Pour cela, vous y découvrirez les commandes et l'analyse de trames correspondant aux résolutions basiques.
8.15 - Domain Name System Security Extensions
Vidéo en anglais de Mr Cisco présentant le protocole de routage DNSSE (Domain Name System Security Extensions).
8.16 - Domain Name System par Mr Cisco
Vidéo en anglais de Mr Cisco présentant le protocole de routage DNS (Domain Name System).
8.17 - Exercice sur DNS
Video présentant, sous forme d'excercice, des cas concrets du protocole DNS (Domain Name System).
8.18 - DNS, adresses et noms
Cette vidéo explique la distinction entre DNS, adresses et noms dans l'Internet.
9 – Suivi du document
Création et suivi de la documentation par _SebF
Modification de la documentation par Emeline
- Relecture et accompagnement sur la création de la documentation
Modification de la documentation par Julien PETIT
- Définition plus précise du flag Z en chapitre 3.2.8.
10 – Discussion autour du protocole DNS
Vous pouvez poser toutes vos questions, faire part de vos remarques et partager vos expériences à propos du protocole DNS. Pour cela, n’hésitez pas à laisser un commentaire ci-dessous :
Salut ! Après que j’ai été surpris par la complexité du DNS bien expliquer par mon professeur! De l’UPL, je me suis vu être contraint de faire des recherches sur celui-ci pour bien appréhender cette notion après avoir tomber sur plusieurs articles parlant sur le DNS, je me suis rendu compte que votre article est intéressant car cela s’explique très facilement.
Bonjour,
Merci pour l’ensemble des informations, c’est propre et clair.
Cdt
Aurélien de Kerviel
Bonjour,
Merci beaucoup.
Beau travail.
Salutations.
Sylvain PASSEMAR
je rajouterait des détails sur les champ nom de chaque RR
selon ce que j’ai observé, « les mots » de chaque nom dans les champs RR sont constitué de 1 octet pour donner la taille du mot puis les caractère du mot avec un zéro pour marquer la fin de ce champ mais j’en suis pas sûr
Lu N-LG,
Voici la définition exacte de la RFC concernant le champ « Name ».
NAME : an owner name, i.e., the name of the node to which this resource record pertains.
The owner name is often implicit, rather than forming an integral part of the RR. For example, many name servers internally form tree or hash structures for the name space, and chain RRs off nodes. The remaining RR parts are the fixed header (type, class, TTL) which is consistent for all RRs, and a variable part (RDATA) that fits the needs of the resource being described.
@+
Sebastien FONTAINE
ce qui m’intéresse c’est la structure binaire des RR pour pouvoir les décoder et a part cette page je n’ai rien trouvé sur la structure des données (il y as un paquet de RFC sur le DNS et je suis un peu perdu)
je n’arrive pas a décoder la « question » dans la trame, au début j’ai pensé que celle ci avait la même structure que les RR mais j’ai l’impression que ce n’est pas le cas
Lu N-LG,
Peux-tu donner un exemple ?
@+
Sebastien FONTAINE
Regare la RFC 1101, elle correspond peux-être à ce que tu recherches.
j’ai trouvé dans le chapitre 5.2 de votre que la request était composé des champs qname qtype et qclass et après une recherche sur internet j’ai trouvé sur https://jameshfisher.com/2016/12/31/dns-protocol.html toutes les informations qui m’ont permis de compléter ma compréhension de la structure des trame
en tout cas ce site est génial, j’ai réussit a comprendre et a utiliser un tas de concepts réseau pour me permettre de faire (enfin il n’est pas tout a fait terminé) un pilote réseau pour système d’exploitation maison
Article très complet sur le dns, beau travail!
ps: faites attention de bien vous relire 😉